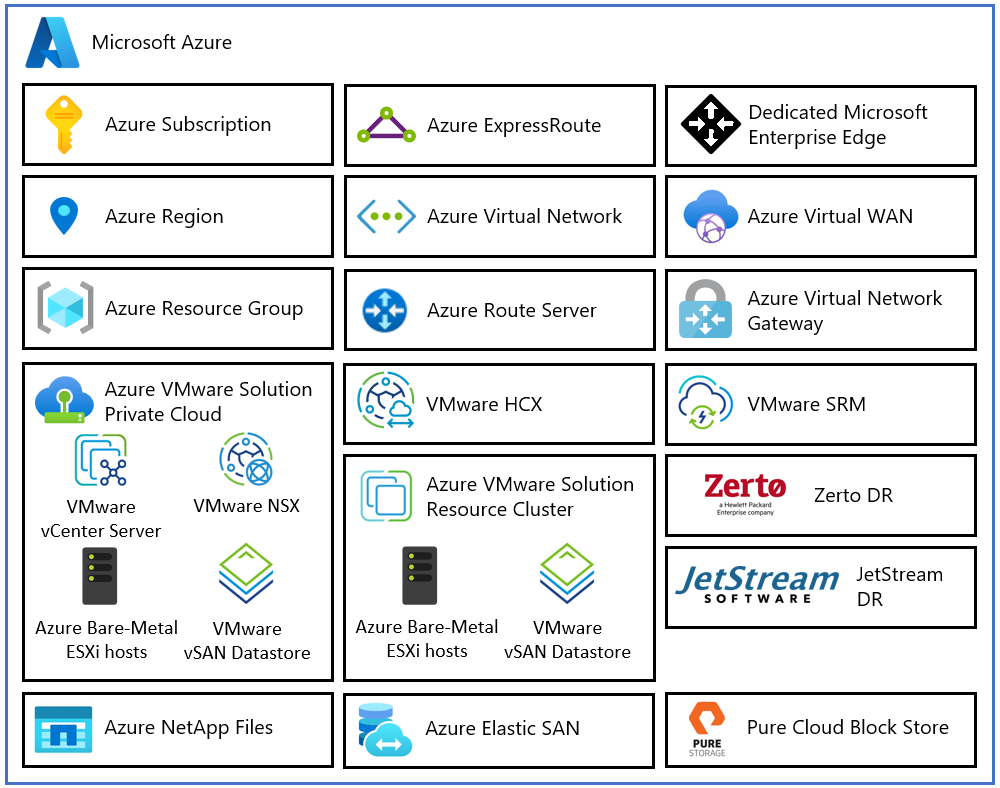
Azure VMware Solution управляет глобальным парком производственных приватных облаков, каждое из которых работает в полноценной управляющей плоскости (control plane) VMware NSX и vCenter Server. Когда, например, кластер VMware NSX Manager теряет кворум, NSX может генерировать множество связанных алармов, однако наблюдаемое воздействие выглядит как одновременный каскадный сбой: обновления плоскости управления и конфигурации прекращаются, работоспособность кластера может деградировать, а некоторые симптомы Edge-узлов или транспортных узлов могут проявляться следом — при этом существующая динамическая маршрутизация Tier-0, как правило, остаётся работоспособной. Иными словами, несколько симптомов могут иметь один общий корневой сбой, который необходимо верифицировать с учётом состояния кластера, работоспособности сервисов, хранилища, состояния Compute Manager и связности транспортных узлов. Без модели, кодирующей направленные зависимости между этими уровнями, набор тревог структурно неотличим от множества независимых одновременных сбоев.
Оператор, обрабатывающий каждую тревогу независимо, продлевает инцидент, повторно проходя один и тот же путь распространения сбоя с каждым действием. В условиях производственных масштабов распространение сбоев NSX стабильно опережает ручную сортировку инцидентов. Система автономного самовосстановления приватного облака Azure VMware Solution — это архитектура управления с замкнутым контуром, созданная для устранения именно этого класса сбоев. Система коррелирует сигналы плоскости управления причинно-следственным образом с использованием динамического графа зависимостей в реальном времени, применяет полный стек политик-шлюзов перед любым автоматическим действием, захватывает ограниченное взаимное исключение перед началом выполнения и независимо верифицирует восстановление прежде, чем закрыть инцидент. В данной статье описываются архитектура системы и принятые проектные решения.
Архитектурные компоненты
Azure VMware Solution — это VMware-валидированный сервис Azure первой стороны от Microsoft, предоставляющий приватные облака с кластерами VMware vSphere на базе выделенной bare-metal инфраструктуры Azure. Это позволяет заказчикам использовать существующие инвестиции в навыки и инструменты VMware, сосредоточившись на разработке и запуске своих VMware-нагрузок в Azure.
Каждый архитектурный компонент Azure VMware Solution выполняет следующие функции:
Azure Subscription — управление доступом, бюджетом и квотами для Azure VMware Solution.
Azure Region — физические местоположения по всему миру, объединяющие центры обработки данных в зоны доступности (AZ), а зоны доступности — в регионы.
Azure Resource Group — контейнер для группировки сервисов и ресурсов Azure в логические группы.
Azure VMware Solution Private Cloud — использует программное обеспечение VMware, включая vCenter Server, программно-определяемые сети NSX, программно-определяемое хранилище vSAN и bare-metal хосты ESXi Azure для предоставления вычислительных ресурсов, сетевых ресурсов и хранилища. Поддерживаются также Azure NetApp Files, Azure Elastic SAN и Pure Cloud Block Store.
Azure VMware Solution Resource Cluster — масштабирует приватное облако за счёт дополнительных bare-metal хостов ESXi и программного обеспечения vSAN.
VMware HCX — обеспечивает мобильность, миграцию и расширение сети.
VMware Site Recovery — обеспечивает автоматизацию аварийного восстановления и репликацию хранилища через vSphere Replication. Также поддерживаются сторонние решения DR — Zerto DR и JetStream DR.
Dedicated Microsoft Enterprise Edge (D-MSEE) — маршрутизатор, обеспечивающий связность между Azure и приватным облаком Azure VMware Solution.
Azure Virtual Network (VNet) — частная сеть для соединения сервисов и ресурсов Azure.
Azure Route Server — позволяет сетевым устройствам обмениваться динамической информацией о маршрутизации с сетями Azure.
Azure Virtual Network Gateway — кросс-облачный шлюз для подключения через IPSec VPN, ExpressRoute и VNet-to-VNet.
Azure ExpressRoute — высокоскоростные приватные подключения между центрами обработки данных Azure и локальной или колокационной инфраструктурой.
Azure Virtual WAN (vWAN) — объединяет функции сетевого взаимодействия, безопасности и маршрутизации в единую глобальную сеть.
Что обеспечивает автономное самовосстановление
Система автономного самовосстановления вводит пять гарантированных на системном уровне свойств корректности, ни одно из которых ранее не существовало как системно-принудительное поведение в пути реагирования на инциденты плоскости управления Azure VMware Solution:
Возможность
Что делает Autonomous Self-Heal
Предыдущее состояние
Ограниченное, верифицируемое время восстановления
Измеряет время от первого скоррелированного сигнала до верифицированного стабильного восстановления.
Инциденты закрывались по завершении действия, а не восстановления.
Целостность сигнала при поступлении
Нормализует события, дедуплицирует источники и подавляет флаппинг перед корреляцией.
Конвейера нормализации не существовало. Инженеры получали необработанный поток тревог.
Выполнение с политикой-шлюзом
Атомарно проверяет окна заморозки, бюджеты риска, радиус проблемы, ограничения скорости и согласования перед выполнением.
Единого атомарного стека шлюзов для ограничений и согласований не существовало.
Доказательная база инцидента с возможностью только дополнения
Сохраняет сигналы, топологию, решения, трассировку workflow и верификацию в структурированной записи.
Доказательства находились в отдельных журналах и с трудом воспроизводились.
Прогрессивная модель доверия
Поддерживает режим только-уведомления, чтобы операторы могли проверить обнаружения и предлагаемые действия перед включением.
Автоматизация была бинарной — не было механизма наблюдения за поведением системы до предоставления полномочий на выполнение.
Принципы проектирования
Автономное самовосстановление вводит семь проектных элементов в операции плоскости управления приватным облаком Azure VMware Solution:
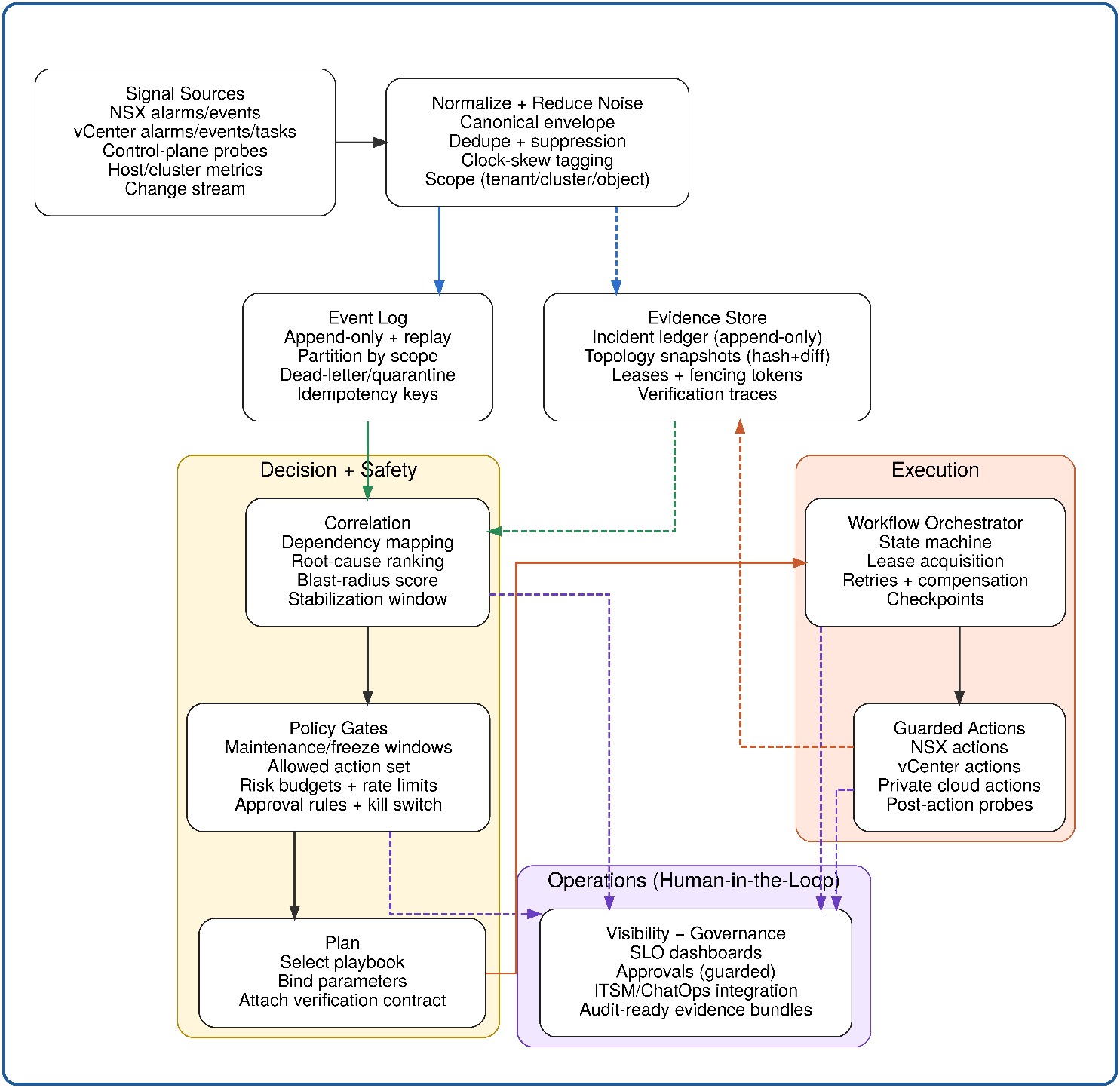
Разделение трёх плоскостей (обнаружение, принятие решений, выполнение) с изоляцией поверхностей сбоя по всему управляющему контуру.
Динамический граф зависимостей реального времени, непрерывно обновляемый из потоков событий VMware NSX и vCenter Server, заменяющий статические наборы правил, которые расходятся с реальной топологией.
Трёхвходная модель причинно-следственной корреляции (сила доказательств, временной порядок, направленность зависимости), отличающая причинно-следственные цепочки от совпадающих событий.
Вычисление радиуса проблемы перед выполнением - входной параметр шлюза, обеспечивающий пропорциональное применение политик до совершения любого действия.
Модель фазовых границ (стабилизация, выполнение, верификация), преобразующая событийные осцилляции в демпфированную петлю обратной связи с гистерезисом.
Структура контракта выполнения (триггер, объявление шлюза, спецификация шагов, контракт верификации), принудительно обеспечивающая допустимость области действия и актуальность топологии как системных ограничений.
Единый журнал с возможностью только дополнения, формирующий идентичные записи для автоматизированных и управляемых людьми путей разрешения инцидентов — для целей управления и воспроизведения после инцидента.
Для сбоев в охватываемой области результат — это ограниченное, воспроизводимое время восстановления в любое время суток без участия оператора. Для сбоев в охватываемой области, где автоматическое устранение не может быть санкционировано, результат — детерминированный пакет доказательств, заменяющий воспоминания инженера структурированной, воспроизводимой передачей дел.
Архитектура: обнаружение, принятие решений и выполнение
Автономное самовосстановление разделяет обнаружение, принятие решений и выполнение на отдельные плоскости с единственными, тестируемыми контрактами между ними. Объединение этих функций — более простой подход — разделяет поверхность сбоя между всеми тремя: ошибка в движке выполнения может повредить доказательства, от которых зависит модель корреляции; всплеск объёма тревог может лишить ресурсов оценщика шлюзов; неправильно настроенный шлюз может заблокировать нормализацию сигналов. Разделение устраняет эти режимы взаимозаражения сбоев.
Плоскость обнаружения преобразует необработанные потоки тревог VMware NSX и vCenter Server в стабильные, дискретные кандидаты на инцидент. Конвейер нормализует форматы событий из разных источников, сворачивает избыточные сигналы и применяет окно задержки для фильтрации переходных изменений состояния. Кандидаты, пересекающие границу плоскости, — это подтверждённые, стабильные единицы, единственная форма, которую модель корреляции способна корректно обработать.
Плоскость принятия решений выполняет причинно-следственную корреляцию по динамическому графу зависимостей приватного облака перед оценкой шлюза, формируя ранжированную гипотезу первопричины с оценками уверенности и вычисленной оценкой радиуса проблемы. Плоскость выдаёт ровно один из двух результатов: санкционированное шлюзом разрешение на выполнение или эскалацию с полным пакетом доказательств.
Плоскость выполнения получает токен, ограниченный минимально жизнеспособной областью сбоя, запускает версионированный идемпотентный контрольно-точечный плейбук и закрывает инцидент только после того, как независимая верификация постусловий подтверждает стабильное восстановление в течение окна стабильности. Каждый переход состояния дополняет журнал инцидента.
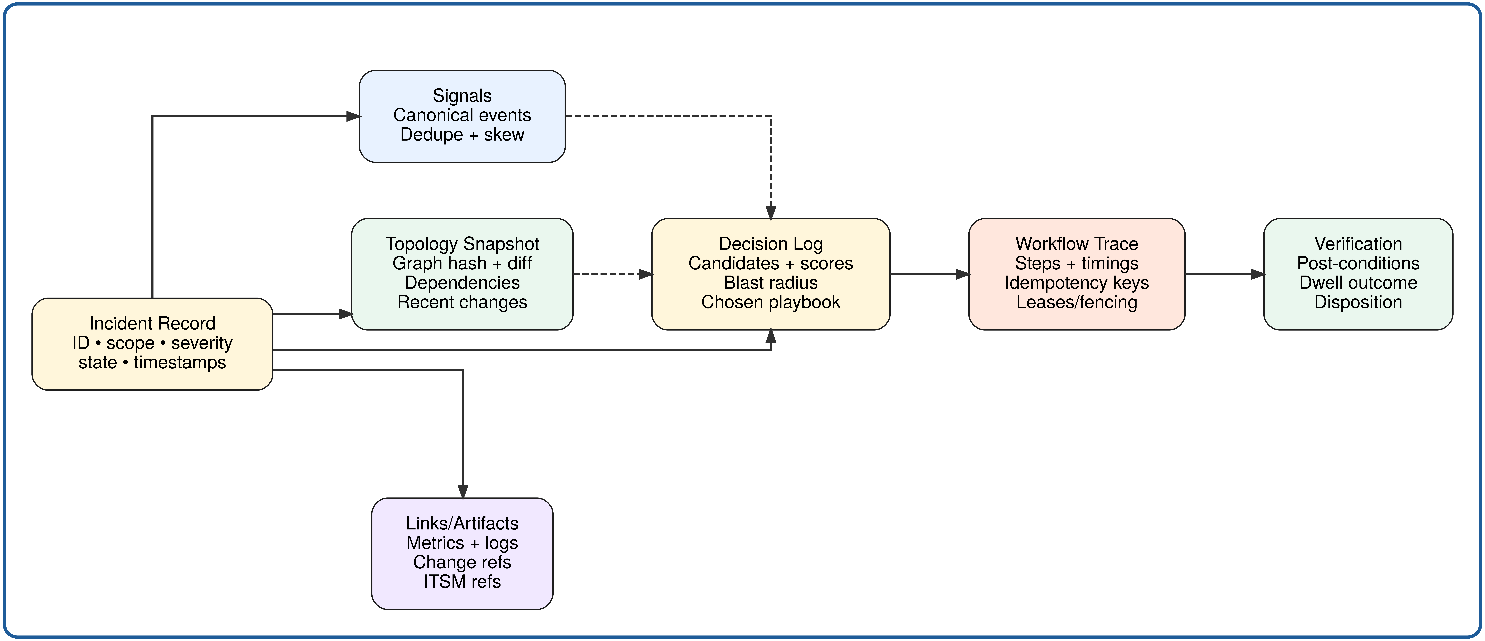
Журнал инцидентов
Автономное самовосстановление формирует структурированный журнал с возможностью только дополнения для каждого инцидента вне зависимости от пути разрешения. Последовательно фиксируются пять категорий: необработанные и нормализованные сигналы с результатами подавления; снимок топологии на момент обнаружения; полная запись решений, включая результаты корреляции, ранжирование первопричин, оценку радиуса проблемы и трассировку оценки шлюза; трассировка workflow с метаданными шагов и идентификаторами аренды; и результат верификации с результатами постусловий и диспозицией окна стабильности.
Автоматизированные и управляемые людьми пути формируют одинаковую структуру записи — это требование управляемости, а не предпочтение проектирования. Воспроизведение детерминировано: по одному и тому же журналу два рецензента реконструируют одинаковую временную шкалу инцидента.
Итог
Автономное самовосстановление обрабатывает определённое подмножество сбоев плоскости управления NSX и vCenter в приватном облаке Azure VMware Solution. Система не обрабатывает сбои плоскости данных, сбои хранилища, сбои гипервизора, аппаратные сбои или сбои плоскости управления вне смоделированного графа зависимостей. Она не запускает произвольные скрипты, не обходит управление доступом на основе ролей и не переопределяет границы изоляции тенантов. Ограниченная область является источником надёжности системы — система, пытающаяся устранять всё подряд, несёт режимы сбоя, пропорциональные её охвату.
Когда автономное самовосстановление не может предпринять действий, формируемый им пакет доказательств обеспечивает полную структурированную передачу для ответа оператора.
Если вы уже знакомы с преимуществами локальных снапшотов для защиты данных в vSAN ESA, значит у вас есть опыт работы с одной из служб в составе объединённого виртуального модуля защиты и восстановления, являющегося частью решения ACC (Advanced Cyber Compliance).
Расширение защиты и восстановления ВМ
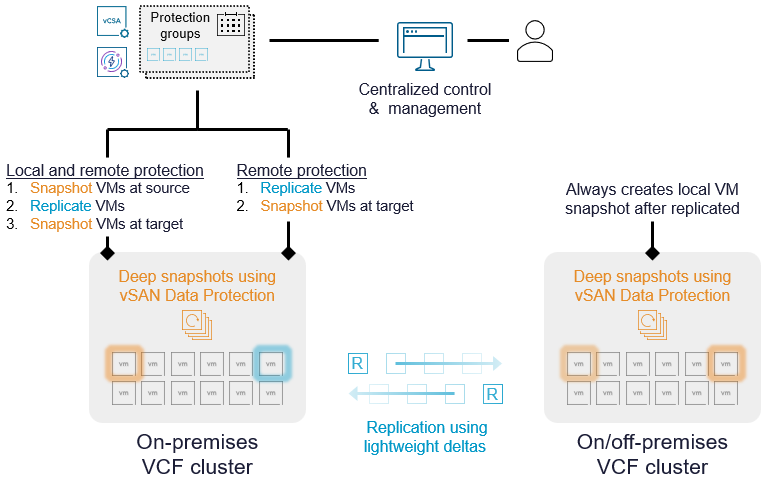
Давайте рассмотрим объединённую ценность защиты данных vSAN и VMware Advanced Cyber Compliance, позволяющую обеспечить надёжное, уверенное восстановление после кибератак и других катастроф. Виртуальный модуль защиты и восстановления, включённый в возможности аварийного восстановления решения Advanced Cyber Compliance, содержит три службы — все объединены в один простой в развертывании и управлении модуль (Virtual Appliance):
Служба снимков vSAN ESA
Расширенная репликация vSphere
Группы защиты и оркестрация восстановления
Сочетание этих служб модуля вместе с возможностями хранения vSAN ESA расширяет возможности для более широкой мультисайтовой защиты и восстановления ваших рабочих нагрузок в VCF.
Настройка вторичного сайта восстановления
В рамках вашей топологии развертывания VCF просто включите ещё один кластер vSAN ESA на втором сайте или в другой локации. Второй сайт подразумевает дополнительную среду vCenter в домене рабочих нагрузок VCF. Для простоты и удобства ссылки назовём эти два сайта «Site A» и «Site B» и развернём их в одном экземпляре VCF, как показано ниже.
Чтобы максимизировать ценность всех трёх упомянутых выше служб и расширить защиту данных vSAN между этими сайтами, вам потребуется лицензировать возможность оркестрации. Возможность оркестрации защиты и восстановления необходима для управления параметрами защиты данных vSAN для групп защиты, которым требуется включать функции репликации.
Имейте в виду, что расширенная репликация vSphere и возможности службы снапшотов vSAN уже включены в лицензирование VCF.
На новом вторичном сайте разверните кластер vSAN ESA для соответствующего vCenter вместе с ещё одним экземпляром объединённого виртуального модуля. Во многих случаях как модули vCenter, так и эти устройства защиты и восстановления устанавливаются в домен управления VCF.
После настройки двух сайтов процесс установления расширенной репликации vSphere между хостами ESX на каждом сайте довольно прост.
Расширение охвата политики защиты
VMware Advanced Cyber Compliance включает полностью оркестрированное аварийное восстановление между локальными сайтами VCF, и благодаря хранилищам данных vSAN ESA на этих нескольких сайтах теперь можно построить более надёжное решение по защите данных и аварийному восстановлению на уровне всего предприятия.
При наличии многосайтовой, объединённой конфигурации Advanced Cyber Compliance и vSAN ESA, группы защиты, которые вы определяете в рамках защиты данных vSAN для локального восстановления, теперь могут воспользоваться двумя дополнительными вариантами (2 и 3 пункты ниже), включающими репликацию и координацию защиты между двумя сайтами:
Локальная защита — защита с помощью снапшотов в пределах одного сайта.
Репликация — репликация данных ВМ на вторичный сайт.
Локальная защита и репликация — репликация данных ВМ между сайтами плюс локальные снапшоты и хранение удалённых снапшотов.
Давайте более подробно рассмотрим пример настройки защиты данных vSAN между двумя сайтами, которую можно использовать для аварийного восстановления, если исходный сайт станет недоступным или выйдет из строя. Для этого примера мы создадим новую группу защиты и пройдём процесс настройки политики, как показано ниже. Процесс настройки состоит всего из нескольких шагов, включая:
Задание свойств политики защиты.
Определение инвентаря защищаемых ВМ.
Настройку расписаний локальных снапшотов.
Настройку параметров репликации и хранения данных между сайтами.
Для типа защиты мы выбрали вариант «Локальная защита и репликация» (Local protection and replication). Это добавляет шаги 4 и 5 (показанные ниже) в определение политики группы защиты соответственно.
Расписания локальных снапшотов (шаг 4) определяют точки восстановления, которые будут доступны для выбранных виртуальных машин на локальном хранилище данных vSAN ESA. Каждая политика группы защиты может включать несколько расписаний, определяющих частоту создания снапшотов и период их хранения.
Примечание: это определение политики группы защиты также использует критерии выбора ВМ, основанные как на шаблонах имён (шаг 2), так и на индивидуальном выборе (шаг 3), показанных на скриншоте выше. Это обеспечивает высокую гибкость при определении состава ВМ, подлежащих защите.
Снапшоты и репликация имеют отдельные параметры конфигурации политики. Данные между сайтами Site A и Site B в данном примере будут реплицироваться независимо от локальных снапшотов, создаваемых по расписанию. Это также означает, что процесс репликации выполняется отдельно от процессов локального создания снапшотов.
С VMware Advanced Cyber Compliance для аварийного восстановления частота репликации vSphere replication — или первичная цель точки восстановления (RPO) — для каждой ВМ может быть минимальной, вплоть до 1 минуты.
При настройке параметров репликации вы также указываете хранение снапшотов на удалённом сайте, определяя глубину восстановления на вашем вторичном сайте. После завершения определения политики группы защиты в интерфейсе защиты данных vSAN вы можете увидеть различные параметры расписаний, хранения и частоты репликации, как показано на скриншоте ниже:
Примечание: группы защиты, определённые с использованием методов защиты данных vSAN, которые включают параметры репликации, будут обнаружены механизмом оркестрации защиты и восстановления и добавлены как записи групп репликации и защиты в инвентарь оркестрации, как указано в информационном блоке на скриншоте выше.
Интеграция с оркестрацией восстановления
Если переключиться на этот интерфейс, вы увидите, что наша политика "Example-Multi-Site-Protection-Group" отображается ниже — она была импортирована в инвентарь групп защиты вместе с существующими группами защиты, определёнными в пользовательском интерфейсе оркестрации защиты и восстановления.
Кроме того, любые виртуальные машины, включённые в группу защиты, определённую с использованием методов защиты данных vSAN, также отображаются в инвентаре Replications и помечаются соответствующим типом, как показано ниже:
В интерфейсе оркестрации, если вам нужно изменить группу защиты, созданную с использованием vSAN data protection, легко перейти обратно в соответствующий интерфейс управления этой группой. Контекстная ссылка для этого отображается на изображении ниже (сразу над выделенной областью Virtual Machines):
Используя совместно защиту данных vSAN и возможности аварийного восстановления VMware Advanced Cyber Compliance в вашем развертывании VCF, вы получаете улучшенную локальную защиту ВМ для оперативного восстановления, а также удалённую защиту ВМ, полезную для целей аварийного восстановления.
В VMware Cloud Foundation (VCF) 9.0 легко упустить из виду относительно новые функции, находящиеся прямо перед глазами. Защита данных в частном облаке в последнее время стала особенно актуальной темой, выходящей далеко за рамки обычных задач восстановления данных. Клиенты ищут практичные стратегии защиты от атак вымогателей и аварийного восстановления с помощью решений, которыми легко управлять в масштабах всей инфраструктуры.
vSAN Data Protection впервые появилась в vSAN 8 U3 как часть VMware Cloud Foundation 5.2. Наиболее часто упускаемый момент — это то, что vSAN Data Protection входит в лицензию VCF!
Почему это важно? Если вы используете vSAN ESA в своей среде VCF, у вас уже есть всё необходимое для локальной защиты рабочих нагрузок с помощью vSAN Data Protection. Это отличный способ дополнить существующие стратегии защиты или создать основу для более комплексной.
Рассмотрим кратко, что может предложить эта локальная защита и как просто и масштабируемо её внедрить.
Простая локальная защита
Как часть лицензии VCF, vSAN Data Protection позволяет использовать снапшоты именно так, как вы всегда хотели. Благодаря встроенному механизму создания снапшотов vSAN ESA, вы можете:
Легко определять группы ВМ и их расписание защиты и хранения — до 200 снапшотов на ВМ.
Создавать согласованные по сбоям снапшоты ВМ с минимальным влиянием на производительность.
Быстро восстанавливать одну или несколько ВМ прямо в vCenter Server через vSphere Client, даже если они были удалены из инвентаря.
Поскольку vSAN Data Protection работает на уровне ВМ, защита и восстановление отдельных VMDK-дисков внутри виртуальной машины пока не поддерживается.
Простое и гибкое восстановление
Причины восстановления данных могут быть разными, и vSAN Data Protection даёт администраторам платформ виртуализации возможность выполнять типовые задачи восстановления без привлечения других команд.
Например, обновление ОС виртуальной машины не удалось или произошла ошибка конфигурации — vSAN Data Protection готова обеспечить быстрое и простое восстановление. Или, допустим, виртуальная машина была случайно удалена из инвентаря. Ранее ни один тип снимков VMware не позволял восстановить снимок удалённой ВМ, но vSAN Data Protection справится и с этим.
Обратите внимание, что восстановление виртуальных машин в демонстрации выше выполняется напрямую в vSphere Client, подключённом к vCenter Server. Не нужно использовать дополнительные приложения, и поскольку процесс основан на уровне ВМ, восстановление интуитивно понятное и безопасное — без сложностей, связанных с восстановлением на основе снимков хранилища (array-based snapshots).
Для клиентов, уже внедривших vSAN Data Protection, такая простота восстановления стала одной из наиболее ценных возможностей решения.
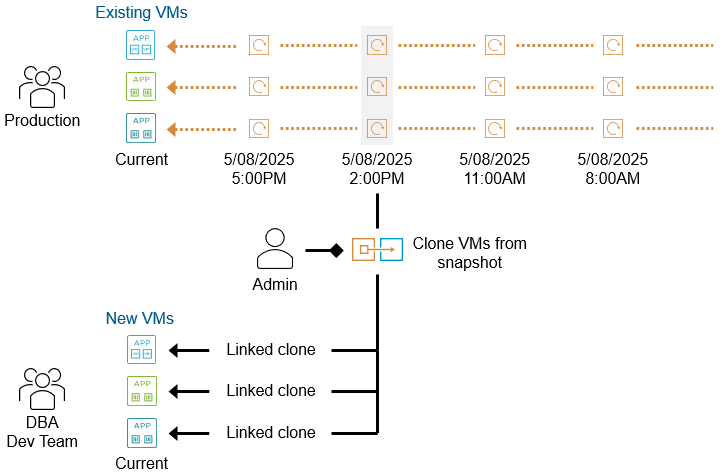
Быстрое и гибкое клонирование
Преимущества автоматизированных снапшотов, создаваемых с помощью vSAN Data Protection, выходят далеко за рамки восстановления данных. С помощью vSAN Data Protection можно легко создавать клоны виртуальных машин из существующих снапшотов. Это чрезвычайно простой и эффективный по использованию пространства способ получить несколько ВМ для различных задач.
Клонирование из снапшотов можно использовать для разработки и тестирования программного обеспечения, а также для администрирования и тестирования приложений. Администраторы платформ виртуализации могут без труда интегрировать эту функцию в повседневные IT-операции и процессы управления жизненным циклом.
Давайте посмотрим, как выглядит такое быстрое клонирование большой базы данных в пользовательском интерфейсе.
Обратите внимание, что клонированная виртуальная машина, созданная из снапшота в vSAN Data Protection, представляет собой связанную копию (linked clone). Такой клон не может быть впоследствии защищён с помощью групп защиты и снапшотов в рамках vSAN Data Protection. Клон можно добавить в группу защиты, однако при следующем цикле защиты для этой группы появится предупреждение «Protection Group Health», указывающее, что создание снапшота для клонированной ВМ не удалось.
Ручные снапшоты таких связанных клонов можно создавать вне vSAN Data Protection (через интерфейс или с помощью VADP), что позволяет решениям резервного копирования, основанным на VADP, защищать эти клоны.
С чего начать
Так как функции защиты данных уже включены в вашу лицензию VCF, как приступить к работе? Рассмотрим краткий план.
Установка виртуального модуля для vSAN Data Protection
Для реализации описанных возможностей требуется установка виртуального модуля (Virtual Appliance) — обычно одного на каждый vCenter Server. Этот виртуальный модуль VMware Live Recovery (VLR) обеспечивает работу службы vSAN Data Protection, входящей в состав VCF, и предоставляет локальную защиту данных. Оно управляет процессом создания и координации снимков, но не участвует в передаче данных и не является единой точкой отказа.
Базовые шаги для развертывания и настройки модуля:
Загрузите виртуальный модуль для защиты данных с портала Broadcom.
Войдите в vSphere Client, подключённый к нужному vCenter Server, и разверните модуль как обычный OVF-шаблон.
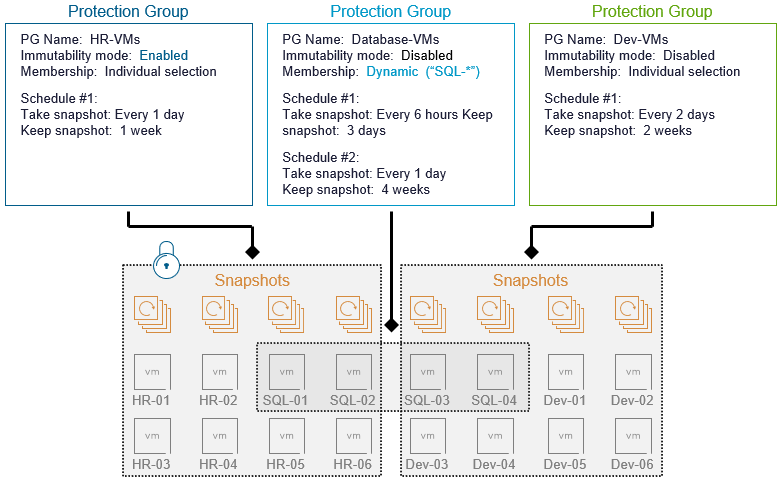
Защита виртуальных машин осуществляется с помощью групп защиты (protection groups), которые определяют желаемую стратегию защиты ВМ. Вы можете управлять тем, какие ВМ будут защищены, как часто выполняется защита, а также настройками хранения снапшотов.
Группы защиты также позволяют указать, должны ли снапшоты быть неизменяемыми (immutable) — всё это настраивается с помощью простого флажка в интерфейсе.
Неизменяемость гарантирует, что снапшоты не могут быть каким-либо образом изменены или удалены. Эта опция обеспечивает базовую защиту от вредоносных действий и служит основой для более продвинутых механизмов киберустойчивости (cyber resilience).
Давайте посмотрим, насколько просто это реализуется в интерфейсе. Сначала рассмотрим настройку группы защиты в vSphere Client.
Группы защиты начинают выполнять заданные параметры сразу после создания первого снапшота. Это отличный пример принципа «настроил и забыл» (set it and forget it), реализованного в vSAN Data Protection, который обеспечивает простое и интуитивное восстановление одной или нескольких виртуальных машин при необходимости.
Рекомендация: если вы используете динамические шаблоны имен ВМ в группах защиты, убедитесь, что виртуальные машины, созданные из снапшотов в vSAN Data Protection, не попадают под этот шаблон. В противном случае будет сгенерировано предупреждение о состоянии группы защиты (Health Alert), указывающее, что связанный клон не может быть защищён в рамках этой группы.
Расширенные возможности в VCF 9.0
В версии VCF 9.0 vSAN Data Protection получила ряд улучшений, которые сделали её ещё более удобной и функциональной.
Единый виртуальный модуль
Независимо от того, используете ли вы только локальную защиту данных через vSAN Data Protection или расширенные возможности репликации и аварийного восстановления (DR), теперь для этого используется единый виртуальный модуль, доступный для загрузки по ссылке.
Он сокращает потребление ресурсов, упрощает управление и позволяет расширять функциональность для DR и защиты от программ-вымогателей путём простого добавления лицензионного ключа.
Защита ВМ на других кластерах vSAN
Хотя vSAN Data Protection обеспечивает простой способ локальной защиты рабочих нагрузок, новая технология, представленная в VCF 9.0, позволяет реплицировать данные на другой кластер vSAN — механизм, известный как vSAN-to-vSAN replication.
Для использования vSAN-to-vSAN репликации требуется дополнительная лицензия (add-on license). Если она отсутствует, вы по-прежнему можете использовать локальную защиту данных с помощью vSAN Data Protection. Однако эта лицензия предоставляет не только возможность удалённой репликации — она также добавляет инструменты для комплексной защиты данных и оркестрации, помогая выполнять требования по аварийному восстановлению (DR) и кибербезопасности.
Иными словами, все базовые возможности локальной защиты вы можете реализовать с помощью vSAN Data Protection. А когда придёт время расширить защиту для сценариев аварийного восстановления (DR) и восстановления после киберинцидентов (cyber recovery), это можно сделать просто — активировав дополнительные возможности с помощью add-on лицензии.
Для ответов на часто задаваемые вопросы о vSAN Data Protection см. раздел «vSAN Data Protection» в актуальной версии vSAN FAQs.
Итоги
Клиенты VCF, использующие vSAN ESA в составе VCF 5.2 или 9.0, уже обладают невероятно мощным инструментом, встроенным в их решение. vSAN Data Protection обеспечивает возможность локальной защиты рабочих нагрузок без необходимости приобретения дополнительных лицензий.
Таги: VMware, vSAN, Storage, Data Protection, Update, Enterprise, Licensing
Команда поддержки VMware в Broadcom полностью привержена тому, чтобы помочь клиентам в процессе обновлений. Поскольку дата окончания общего срока поддержки VMware vSphere 7 наступила 2 октября 2025 года, многие пользователи обращаются к вендору в поисках лучших практик и пошаговых руководств по обновлению. И на этот раз речь идет не только об обновлениях с VMware vSphere 7 до VMware vSphere 8. Наблюдается активный рост подготовки клиентов к миграции с vSphere 7 на VMware Cloud Foundation (VCF) 9.0.
Планирование и выполнение обновлений может вызывать стресс, поэтому в VMware решили, что новый набор инструментов для обновления будет полезен клиентам. Чтобы сделать процесс максимально гладким, техническая команда VMware подготовила полезные ресурсы для подготовки к апгрейдам, которые помогут обеспечить миграцию инфраструктуры без серьезных проблем.
Чтобы помочь в этом процессе, каким бы он ни был, были подготовлены руководства в формате статей базы знаний (KB), которые проведут вас через весь процесс от начала до конца. Этот широкий набор статей базы знаний по обновлениям продуктов предоставляет простые, пошаговые инструкции по процессу обновления, выделяя области, требующие особого внимания, на каждом из следующих этапов:
Подготовка к обновлению
Последовательность и порядок выполнения апгрейда
Необходимые действия после переезда и миграции
Ниже приведен набор статей базы знаний об обновлениях, с которым настоятельно рекомендуется ознакомиться до проведения обновления инфраструктуры vSphere и других компонентов платформы VCF.
Современная инфраструктура не прощает простоев. Любая потеря доступности данных — это не только бизнес-риск, но и вопрос репутации. VMware vSAN, будучи ядром гиперконвергентной архитектуры VMware Cloud Foundation, всегда стремился обеспечивать высокую доступность и устойчивость хранения. Но с появлением Express Storage Architecture (ESA) подход к отказоустойчивости изменился фундаментально.
Документ vSAN Availability Technologies (часть VCF 9.0) описывает, как именно реализована устойчивость на уровне данных, сетей и устройств. Разберём, какие технологии стоят за доступностью vSAN, и почему переход к ESA меняет правила игры.
Архитектура отказоустойчивости: OSA против ESA
OSA — классика, но с ограничениями
Original Storage Architecture (OSA) — традиционный вариант vSAN, основанный на концепции дисковых групп (disk groups):
Одно кэш-устройство (SSD)
Несколько накопителей ёмкости (HDD/SSD)
Проблема в том, что выход из строя кеш-диска делает всю группу недоступной. Кроме того, классическая зеркальная защита (RAID-1) неэффективна по ёмкости: чтобы выдержать один отказ, приходится хранить копию 1:1.
ESA — новое поколение хранения
Express Storage Architecture (ESA) ломает эту модель:
Нет больше disk groups — каждый накопитель независим.
Встроен мониторинг NVMe-износа, зеркалирование метаданных и прогноз отказов устройств.
В результате ESA уменьшает "зону взрыва" при сбое и повышает эффективность хранения до 30–50 %, особенно при политике FTT=2.
Как vSAN обеспечивает доступность данных
Всё в vSAN строится вокруг объектов (диски ВМ, swap, конфигурации). Каждый объект состоит из компонентов, которые распределяются по узлам.
Доступность объекта определяется параметром FTT (Failures To Tolerate) — числом отказов, которые система выдержит без потери данных.
Например:
FTT=1 (RAID-1) — один отказ хоста или диска.
FTT=2 (RAID-6) — два отказа одновременно.
RAID-5/6 обеспечивает ту же устойчивость, но с меньшими затратами ёмкости.
Механизм кворума
Каждый компонент имеет "голос". Объект считается доступным, если более 50 % голосов доступны. Это предотвращает split-brain-ситуации, когда две части кластера считают себя активными.
В сценариях 2-Node или stretched-cluster добавляется witness-компонент — виртуальный "свидетель", решающий, какая часть кластера останется активной.
Домены отказов и географическая устойчивость
vSAN позволяет группировать узлы в домены отказов — например, по стойкам, стойкам или площадкам. Данные и компоненты одной ВМ никогда не размещаются в пределах одного домена, что исключает потерю данных при отказе стойки или сайта.
В растянутом кластере (stretched cluster) домены соответствуют сайтам, а witness appliance располагается в третьей зоне для арбитража.
Рекомендация: проектируйте кластер не по минимуму (3–4 узла), а с запасом. Например, для FTT=2 нужно минимум 6 узлов, но VMware рекомендует 7, чтобы система могла восстановить избыточность без потери устойчивости.
Поведение при сбоях: состояния компонентов
vSAN отслеживает каждое состояние компонентов:
Состояние
Описание
Active
Компонент доступен и синхронизирован
Absent
Недоступен (например, временный сбой сети)
Degraded
Компонент повреждён, требуется восстановление
Active-Stale
Компонент доступен, но содержит устаревшие данные
Reconfiguring
Идёт перестройка или изменение политики
Компоненты в состоянии Absent ждут по умолчанию 60 минут перед восстановлением — чтобы избежать лишнего трафика из-за кратковременных сбоев.
Если восстановление невозможно, создаётся новая копия на другом узле.
Сеть как основа устойчивости
vSAN — это распределённое хранилище, и его надёжность напрямую зависит от сети.
Транспорт — TCP/unicast с внутренним протоколом Reliable Datagram Transport (RDT).
Поддерживается RDMA (RoCE v2) для минимизации задержек.
Рекомендуется:
2 NIC на каждый хост;
Подключение к разным коммутаторам;
Active/Standby teaming для vSAN-трафика (предсказуемые пути).
Если часть сети теряет связность, vSAN формирует partition groups и использует кворум, чтобы определить, какая группа "основная". vSAN тесно интегрирован с vSphere HA, что обеспечивает синхронное понимание состояния сети и автоматический рестарт ВМ при отказах.
Ресинхронизация и обслуживание
Resync (восстановление)
Когда хост возвращается в строй или изменяется политика, vSAN ресинхронизирует данные для восстановления FTT-уровня. В ESA ресинхронизация стала интеллектуальной и возобновляемой (resumable) — меньше нагрузка на сеть и диски.
Maintenance Mode
При вводе хоста в обслуживание доступны три режима:
Full Data Migration — полная миграция данных (долго, безопасно).
Ensure Accessibility — минимальный перенос для сохранения доступности (дефолт).
No Data Migration — без переноса (быстро, рискованно).
ESA использует durability components, чтобы временно сохранить данные и ускорить возврат в строй.
Предиктивное обслуживание и мониторинг
VMware внедрила целый ряд механизмов прогнозирования и диагностики:
Degraded Device Handling (DDH) — анализ деградации накопителей по задержкам и ошибкам до фактического отказа.
NVMe Endurance Tracking — контроль износа NVMe с предупреждениями в vCenter.
Low-Level Metadata Resilience — зеркалирование метаданных для защиты от URE-ошибок.
Proactive Hardware Management — интеграция с OEM-телеметрией и предупреждения через Skyline Health.
Эти механизмы в ESA работают точнее и с меньшими ложными срабатываниями по сравнению с OSA.
Disaster Recovery — восстановление после катастрофы (вторая площадка, репликация, резервное копирование).
vSAN отвечает за первое. Для второго используются VMware SRM, vSphere Replication и внешние DR-решения. Однако комбинация vSAN ESA + stretched cluster уже позволяет реализовать site-level resilience без отдельного DR-инструмента.
Практические рекомендации
Используйте ESA при проектировании новых кластеров.
Современные NVMe-узлы и сети 25 GbE позволяют реализовать отказоустойчивость без потери производительности.
Проектируйте с запасом по хостам.
Один дополнительный узел обеспечит восстановление без снижения FTT-уровня.
Настройте отказоустойчивую сеть.
Два интерфейса, разные коммутаторы, Route Based on Port ID — минимальные требования для надёжного vSAN-трафика.
Следите за здоровьем устройств.
Активируйте DDH и NVMe Endurance Monitoring, используйте Skyline Health для предиктивного анализа.
Планируйте обслуживание грамотно.
Режим Ensure Accessibility — оптимальный баланс между безопасностью и скоростью.
Заключение
VMware vSAN уже давно стал стандартом для гиперконвергентных систем, но именно с Express Storage Architecture он сделал шаг от "устойчивости" к "самоисцеляемости". ESA сочетает erasure coding, предиктивную аналитику и глубокую интеграцию с платформой vSphere, обеспечивая устойчивость, производительность и эффективность хранения. Для архитекторов и инженеров это значит одно: устойчивость теперь проектируется не как надстройка, а как неотъемлемая часть самой архитектуры хранения.
Таги: VMware, vSAN, Availability, HA, DR, Storage, Whitepaper
В современных ИТ-системах шифрование данных стало обязательным элементом защиты информации. Цель шифрования — гарантировать, что данные могут прочитать только системы, обладающие нужными криптографическими ключами. Любой, не имеющий ключей доступа, увидит лишь бессмысленный набор символов, поскольку информация надёжно зашифрована устойчивым алгоритмом AES-256. VMware vSAN поддерживает два уровня шифрования для повышения безопасности кластерного хранения данных: шифрование данных на носителях (Data-at-Rest Encryption) и шифрование данных при передаче (Data-in-Transit Encryption). Эти механизмы позволяют защитить данные как в состоянии покоя (на дисках), так и в движении (между узлами кластера). В результате vSAN помогает организациям соответствовать требованиям регуляторов и предотвращать несанкционированный доступ к данным, например, при краже носителей или перехвате сетевого трафика.
Архитектура шифрования vSAN включает несколько ключевых элементов: внешний или встроенный сервер управления ключами (KMS), сервер VMware vCenter, гипервизоры ESXi в составе vSAN-кластера и собственно криптографические модули в ядре гипервизора. Внешний KMS-сервер (совместимый с протоколом KMIP), либо встроенный поставщик ключей vSphere NKP, обеспечивает генерацию и хранение мастер-ключей шифрования. vCenter Server отвечает за интеграцию с KMS: именно vCenter устанавливает доверенные отношения (обмен сертификатами) с сервером ключей и координирует выдачу ключей хостам ESXi. Каждый узел ESXi, входящий в шифрованный кластер vSAN, содержит встроенный криптомодуль VMkernel (сертифицированный по требованиям FIPS), который выполняет операции шифрования и дешифрования данных на стороне гипервизора.
Распределение ключей
При включении шифрования vSAN на кластере vCenter запрашивает у KMS два ключа для данного кластера: ключ шифрования ключей (Key Encryption Key, KEK) и ключ хоста (Host Key). KEK играет роль мастер-ключа: с его помощью будут шифроваться все остальные ключи (например, ключи данных). Host Key предназначен для защиты дампов памяти (core dumps) и других служебных данных хоста. После получения этих ключей vCenter передаёт информацию о KMS и идентификаторы ключей (ID) всем хостам кластера. Каждый узел ESXi устанавливает прямое соединение с KMS (по протоколу KMIP) и получает актуальные копии KEK и Host Key, помещая их в защищённый кэш памяти.
Важно: сами ключи не сохраняются на диске хоста, они хранятся только в оперативной памяти или, при наличии, в аппаратном модуле TPM на узле. Это означает, что при перезагрузке хоста ключи стираются из памяти и в общем случае должны быть вновь запрошены у KMS, прежде чем хост сможет монтировать зашифрованное хранилище.
Ключи данных (DEK)
Помимо вышеупомянутых кластерных ключей, каждый диск или объект данных получает свой собственный ключ шифрования данных (Data Encryption Key, DEK). В оригинальной архитектуре хранения vSAN (OSA) гипервизор генерирует уникальный DEK (алгоритм XTS-AES-256) для каждого физического диска в дисковой группе. Эти ключи оборачиваются (wrap) с помощью кластерного KEK и сохраняются в метаданных, что позволяет безопасно хранить ключи на дисках: получить «сырой» DEK можно только расшифровав его при помощи KEK. В более новой архитектуре vSAN ESA подход несколько отличается: используется единый ключ шифрования кластера, но при этом для различных объектов данных применяются уникальные производные ключи. Благодаря этому данные каждой виртуальной машины шифруются своим ключом, даже если в основе лежит общий кластерный ключ. В обоих случаях vSAN обеспечивает надёжную защиту: компрометация одного ключа не даст злоумышленнику доступа ко всему массиву данных.
Роль гипервизора и производительность
Шифрование в vSAN реализовано на уровне ядра ESXi, то есть прозрачно для виртуальных машин. Гипервизор использует сертифицированный криптографический модуль VMkernel, прошедший все необходимые проверки по стандарту FIPS 140-2 (а в новых версиях — и FIPS 140-3). Все операции шифрования выполняются с использованием аппаратного ускорения AES-NI, что минимизирует влияние на производительность системы. Опыт показывает, что нагрузка на CPU и задержки ввода-вывода при включении шифрования vSAN обычно незначительны и хорошо масштабируются с ростом числа ядер и современных процессоров. В свежей архитектуре ESA эффективность ещё выше: благодаря более оптимальному расположению слоя шифрования в стеке vSAN, для той же нагрузки требуется меньше CPU-циклов и операций, чем в классической архитектуре OSA.
Управление доступом
Стоит упомянуть, что управление шифрованием в vSAN встроено в систему ролей и привилегий vCenter. Только пользователи с особыми правами (Cryptographic administrator) могут настраивать KMS и включать/отключать шифрование на кластере. Это добавляет дополнительный уровень безопасности: случайный администратор без соответствующих привилегий даже не увидит опцию включения шифрования в интерфейсе. Разграничение доступа гарантирует, что ключи шифрования и связанные операции контролируются ограниченным кругом доверенных администраторов.
Шифрование данных на носителях (vSAN Data-at-Rest Encryption)
Этот тип шифрования обеспечивает защиту всех данных, хранящихся в vSAN-датасторе. Включение функции означает, что вся информация, записываемая на диски кластера, автоматически шифруется на последнем этапе ввода-вывода перед сохранением на устройство. При чтении данные расшифровываются гипервизором прозрачно для виртуальных машин – приложения и ОС внутри ВМ не осведомлены о том, что данные шифруются. Главное назначение Data-at-Rest Encryption – обезопасить данные на случай, если накопитель будет изъят из системы (например, при краже или некорректной утилизации дисков).
Без соответствующих ключей злоумышленник не сможет прочитать информацию с отключенного от кластера диска. Шифрование «на покое» не требует специальных самошифрующихся дисков – vSAN осуществляет его программно, используя собственные криптомодули, и совместимо как с гибридными, так и полностью флэш-конфигурациями хранилища.
Принцип работы: в оригинальной реализации OSA шифрование данных происходит после всех операций дедупликации и сжатия, то есть уже на «выходе» перед записью на носитель. Такой подход позволяет сохранить эффективность экономии места: данные сначала сжимаются и устраняются дубликаты, и лишь затем шифруются, благодаря чему коэффициенты дедупликации/сжатия не страдают. В архитектуре ESA шифрование интегрировано выше по стеку – на уровне кэша – но всё равно после выполнения компрессии данных.
То есть в ESA шифрование также не препятствует сжатию. Однако особенностью ESA является то, что все данные, покидающие узел, уже зашифрованы высокоуровневым ключом кластера (что частично перекрывает и трафик между узлами – см. ниже). Тем не менее для обеспечения максимальной криптостойкости vSAN ESA по-прежнему поддерживает отдельный механизм Data-in-Transit Encryption для уникального шифрования каждого сетевого пакета.
Включение и поддержка: шифрование данных на носителях включается на уровне всего кластера vSAN – достаточно установить флажок «Data-at-Rest Encryption» в настройках служб vSAN для выбранного кластера. Данная возможность доступна только при наличии лицензии vSAN Enterprise или выше.
В традиционной архитектуре OSA шифрование можно включать как при создании нового кластера, так и на уже работающем кластере. В последнем случае vSAN выполнит поочерёдное перевоспроизведение данных с каждого диска (evacuation) и форматирование дисковых групп в зашифрованном виде, что потребует определённых затрат ресурсов и времени. В архитектуре ESA, напротив, решение о шифровании принимается только на этапе создания кластера и не может быть изменено позднее без полной перестройки хранилища. Это связано с тем, что в ESA шифрование глубоко интегрировано в работу кластера, обеспечивая максимальную производительность, но и требуя фиксации режима на старте. В обоих случаях, после включения, сервис шифрования прозрачно работает со всеми остальными функциями vSAN (в том числе со снапшотами, клонированием, vMotion и т.д.) и практически не влияет на операционную деятельность кластера.
Шифрование данных при передаче (vSAN Data-in-Transit Encryption)
Второй компонент системы безопасности vSAN – это шифрование сетевого трафика между узлами хранения. Функция Data-in-Transit Encryption гарантирует, что все данные, пересылаемые по сети между хостами vSAN, будут зашифрованы средствами гипервизора.
Это особенно важно, если сеть хранения не полностью изолирована или если требуется соответствовать строгим стандартам по защите данных в транзите. Механизм шифрования трафика не требует KMS: при включении этой опции хосты vSAN самостоятельно генерируют и обмениваются симметричными ключами для установления защищённых каналов. Процесс полностью автоматизирован и не требует участия администратора – достаточно активировать настройку в параметрах кластера.
Data-in-Transit Encryption впервые появилась в vSAN 7 Update 1 и доступна для кластеров как с OSA, так и с ESA. В случае OSA администратор может независимо включить шифрование трафика (оно не зависит от шифрования на дисках, но для полноты защиты желательно задействовать оба механизма). В случае ESA отдельного переключателя может не потребоваться: при создании кластера с шифрованием данные «на лету» фактически уже будут выходить из узлов зашифрованными единым высокоуровневым ключом. Однако, чтобы каждый сетевой пакет имел уникальный криптографический отпечаток, ESA по-прежнему предусматривает опцию Data-in-Transit (она остаётся активной в интерфейсе и при включении обеспечит дополнительную уникализацию шифрования каждого пакета). Следует учесть, что на момент выпуска vSAN 9.0 в составе VCF 9.0 шифрование трафика поддерживается только для обычных (HCI) кластеров vSAN и недоступно для т. н. disaggregated (выделенных storage-only) кластеров.
С технической точки зрения, Data-in-Transit Encryption использует те же проверенные криптомодули, сертифицированные по FIPS 140-2/3, что и шифрование данных на дисках. При активации этой функции vSAN автоматически выполняет взаимную аутентификацию хостов и устанавливает между ними защищённые сессии с помощью динамически создаваемых ключей. Когда новый узел присоединяется к шифрованному кластеру, для него генерируются необходимые ключи и он аутентифицируется существующими участниками; при исключении узла его ключи отзываются, и трафик больше не шифруется для него. Всё это происходит «под капотом», не требуя ручной настройки. В результате даже при потенциальном перехвате пакетов vSAN-трафика на уровне сети, извлечь из них полезные данные не представляется возможным.
Для использования шифрования данных на vSAN необходим сервер управления ключами (Key Management Server, KMS), совместимый со стандартом KMIP 1.1+. Исключение составляет вариант применения встроенного поставщика ключей vSphere (Native Key Provider, NKP), который появился начиная с vSphere 7.0 U2. Внешний KMS может быть программным или аппаратным (множество сторонних решений сертифицировано для работы с vSAN), но в любом случае требуется лицензия не ниже vSAN Enterprise.
Перед включением шифрования администратор должен зарегистрировать KMS в настройках vCenter: добавить информацию о сервере и установить доверие между vCenter и KMS. Обычно настройка доверия реализуется через обмен сертификатами: vCenter либо получает от KMS корневой сертификат (Root CA) для проверки подлинности, либо отправляет на KMS сгенерированный им запрос на сертификат (CSR) для подписи. В результате KMS и vCenter обмениваются удостоверяющими сертификатами и устанавливают защищённый канал. После этого vCenter может выступать клиентом KMS и запрашивать ключи.
В конфигурации с Native Key Provider процесс ещё проще: NKP разворачивается непосредственно в vCenter, генерируя мастер-ключ локально, поэтому внешний сервер не нужен. Однако даже в этом случае рекомендуется экспортировать (зарезервировать) копию ключа NKP во внешнее безопасное место, чтобы избежать потери ключей в случае сбоя vCenter.
Запрос и кэширование ключей
Как только доверие (trust) между vCenter и KMS установлено, можно активировать шифрование vSAN на уровне кластера. При этом vCenter от имени кластера делает запрос в KMS на выдачу необходимых ключей (KEK и Host Key) и распределяет их идентификаторы хостам, как описано выше. Каждый ESXi узел соединяется с KMS напрямую для получения своих ключей. На период нормальной работы vSAN-хосты обмениваются ключами с KMS напрямую, без участия vCenter.
Это означает, что после первоначальной настройки для ежедневной работы кластера шифрования доступность vCenter не критична – даже если vCenter временно выключен, хосты будут продолжать шифровать/расшифровывать данные, используя ранее полученные ключи. Однако vCenter нужен для проведения операций управления ключами (например, генерации новых ключей, смены KMS и пр.). Полученные ключи хранятся на хостах в памяти, а при наличии TPM-модуля – ещё и в его защищённом хранилище, что позволяет пережить перезагрузку хоста без немедленного запроса к KMS.
VMware настоятельно рекомендует оснащать все узлы vSAN доверенными платформенными модулями TPM 2.0, чтобы обеспечить устойчивость к отказу KMS: если KMS временно недоступен, хосты с TPM смогут перезапускаться и монтировать зашифрованное хранилище, используя кешированные в TPM ключи.
Лучшие практики KMS
В контексте vSAN есть важное правило: не размещать сам KMS на том же зашифрованном vSAN-хранилище, которое он обслуживает. Иначе возникает круговая зависимость: при отключении кластера или перезагрузке узлов KMS сам окажется недоступен (ведь он работал как ВМ на этом хранилище), и хосты не смогут получить ключи для расшифровки датасторов.
Лучше всего развернуть кластер KMS вне шифруемого кластера (например, на отдельной инфраструктуре или как облачный сервис) либо воспользоваться внешним NKP от другого vCenter. Также желательно настроить кластер из нескольких узлов KMS (для отказоустойчивости) либо, в случае NKP, надёжно сохранить резервную копию ключа (через функцию экспорта в UI vCenter).
При интеграции с KMS крайне важна корректная сетевая настройка: все хосты vSAN-кластера должны иметь прямой доступ к серверу KMS (обычно по протоколу TLS на порт 5696). В связке с KMS задействуйте DNS-имя для обращения (вместо IP) – это упростит перенастройку в случае смены адресов KMS и снизит риск проблем с подключением.
vSphere Native Key Provider
Этот встроенный механизм управления ключами в vCenter заслуживает отдельного упоминания. NKP позволяет обойтись без развертывания отдельного KMS-сервера, что особенно привлекательно для небольших компаний или филиалов. VMware поддерживает использование NKP для шифрования vSAN начиная с версии 7.0 U2. По сути, NKP хранит мастер-ключ в базе данных vCenter (в зашифрованном виде) и обеспечивает необходимые функции выдачи ключей гипервизорам. При включении шифрования vSAN с NKP процесс выдачи ключей аналогичен: vCenter генерирует KEK и распределяет его на хосты. Разница в том, что здесь нет внешнего сервера – все операции выполняются средствами самого vCenter.
Несмотря на удобство, у NKP есть ограничения (например, отсутствие поддержки внешних интерфейсов KMIP для сторонних приложений), поэтому для крупных сред на долгосрочной основе часто выбирают полноценный внешний KMS. Тем не менее, NKP – это простой способ быстро задействовать шифрование без дополнительных затрат, и он идеально подходит для многих случаев использования.
После того как кластер vSAN сконфигурирован для шифрования и получены необходимые ключи, каждая операция записи данных проходит через этап шифрования в гипервизоре. Рассмотрим упрощённо этот процесс на примере OSA (Original Storage Architecture):
Получение блока данных. Виртуальная машина записывает данные на диск vSAN, которые через виртуальный контроллер поступают на слой vSAN внутри ESXi. Там данные сначала обрабатываются сервисами оптимизации – например, вычисляются хеши для дедупликации и выполняется сжатие (если эти функции включены на кластере).
Шифрование блока. Когда очередь дошла до фактической записи блока на устройство, гипервизор обращается к ключу данных (DEK), связанному с целевым диском, и шифрует блок по алгоритму AES-256 (режим XTS) с помощью этого DEK. Как упоминалось, в OSA у каждого диска свой DEK, поэтому даже два диска одного узла шифруют данные разными ключами. Шифрование происходит на уровне VMkernel, используя AES-NI, и добавляет минимальную задержку.
Запись на устройство. Зашифрованный блок записывается в кеш или напрямую на SSD в составе дисковой группы. На носитель попадают только зашифрованные данные; никакой незашифрованной копии информации на диске не сохраняется. Метаданные vSAN также могут быть зашифрованы или содержать ссылки на ключ (например, KEK_ID), но без владения самим ключом извлечь полезную информацию из зашифрованного блока невозможно.
В архитектуре ESA процесс схож, с тем отличием, что шифрование происходит сразу после сжатия, ещё на высокоуровневом слое ввода-вывода. Это означает, что данные выходят из узла уже шифрованными кластерным ключом. При наличии Data-in-Transit Encryption vSAN накладывает дополнительное пакетное шифрование: каждый сетевой пакет между хостами шифруется с использованием симметрических ключей сеанса, которые регулярно обновляются. Таким образом, данные остаются зашифрованы как при хранении, так и при передаче по сети, что создаёт многослойную защиту (end-to-end encryption).
Чтение данных (дешифрование)
Обратный процесс столь же прозрачен. Когда виртуальная машина запрашивает данные из vSAN, гипервизор на каждом затронутом хосте находит нужные зашифрованные блоки на дисках и считывает их. Прежде чем передать данные наверх VM, гипервизор с помощью соответствующего DEK выполняет расшифровку каждого блока в памяти. Расшифрованная информация проходит через механизмы пост-обработки (восстановление сжатых данных, сборка из дедуплицированных сегментов) и отправляется виртуальной машине. Для ВМ этот процесс невидим – она получает привычный для себя блок данных, не зная, что на физическом носителе он хранится в зашифрованном виде. Если задействовано шифрование трафика, то данные могут передаваться между узлами в зашифрованном виде и расшифровываются только на том хосте, который читает их для виртуальной машины-потребителя.
Устойчивость к сбоям
При нормальной работе все операции шифрования/дешифрования происходят мгновенно для пользователя. Но стоит рассмотреть ситуацию с потенциальным сбоем KMS или перезагрузкой узла. Как отмечалось ранее, хосты кэшируют полученные ключи (KEK, Host Key и необходимые DEK) в памяти или TPM, поэтому кратковременное отключение KMS не влияет на работающий кластер.
Виртуальные машины продолжат и читать, и записывать данные, пользуясь уже загруженными ключами. Проблемы могут возникнуть, если перезагрузить хост при недоступном KMS: после перезапуска узел не сможет получить свои ключи для монтирования дисковых групп, и его локальные компоненты хранилища останутся офлайн до восстановления связи с KMS. Именно поэтому, как уже упоминалось, рекомендуется иметь резервный KMS (или NKP) и TPM-модули на узлах, чтобы повысить отказоустойчивость системы шифрования.
Безопасность криптосистемы во многом зависит от регулярной смены ключей. VMware vSAN предоставляет администраторам возможность проводить плановую ротацию ключей шифрования без простоя и с минимальным влиянием на работу кластера. Поддерживаются два режима: «мелкая» ротация (Shallow Rekey) и «глубокая» ротация (Deep Rekey). При shallow rekey генерируется новый мастер-ключ KEK, после чего все ключи данных (DEK) перешифровываются этим новым KEK (старый KEK уничтожается). Важно, что сами DEK при этом не меняются, поэтому операция выполняется относительно быстро: vSAN просто обновляет ключи в памяти хостов и в метаданных, не перестраивая все данные на дисках. Shallow rekey обычно используют для регулярной смены ключей в целях комплаенса (например, раз в квартал или при смене ответственного администратора).
Deep rekey, напротив, предполагает полную замену всех ключей: генерируются новые DEK для каждого объекта/диска, и все данные кластера постепенно перераспределяются и шифруются уже под новыми ключами. Такая операция более ресурсоёмка, фактически аналогична повторному шифрованию всего объёма данных, и может занять продолжительное время на крупных массивах. Глубокую ротацию имеет смысл выполнять редко – например, при подозрении на компрометацию старых ключей или после аварийного восстановления системы, когда есть риск утечки ключевой информации. Оба типа рекея можно инициировать через интерфейс vCenter (в настройках кластера vSAN есть опция «Generate new encryption keys») или с помощью PowerCLI-скриптов. При этом для shallow rekey виртуальные машины могут продолжать работать без простоев, а deep rekey обычно тоже выполняется онлайн, хотя и создаёт повышенную нагрузку на подсистему хранения.
Смена KMS и экспорт ключей
Если возникает необходимость поменять используемый KMS (например, миграция на другого вендора или переход от внешнего KMS к встроенному NKP), vSAN упрощает эту процедуру. Администратор добавляет новый KMS в vCenter и обозначает его активным для данного кластера. vSAN автоматически выполнит shallow rekey: запросит новый KEK у уже доверенного нового KMS и переведёт кластер на использование этого ключа, перешифровав им все старые DEK. Благодаря этому переключение ключевого сервиса происходит прозрачно, без остановки работы хранилища. Тем не менее, после замены KMS настоятельно рекомендуется удостовериться, что старый KMS более недоступен хостам (во избежание путаницы) и сделать резервную копию конфигурации нового KMS/NKP.
При использовании vSphere Native Key Provider важно регулярно экспортировать зашифрованную копию ключа NKP (через интерфейс vCenter) и хранить её в безопасном месте. Это позволит восстановить доступ к зашифрованному vSAN, если vCenter выйдет из строя и потребуется его переустановка. В случае же аппаратного KMS, как правило, достаточно держать под рукой актуальные резервные копии самого сервера KMS (или использовать кластер KMS из нескольких узлов для отказоустойчивости).
Безопасное удаление данных
Одним из побочных преимуществ внедрения шифрования является упрощение процедуры безопасной утилизации носителей. vSAN предлагает опцию Secure Disk Wipe для случаев, когда необходимо вывести диск из эксплуатации или изъять узел из кластера. При включенной функции шифрования проще всего выполнить «очистку» диска путем сброса ключей: как только DEK данного носителя уничтожен (либо кластерный KEK перегенерирован), все данные на диске навсегда остаются в зашифрованном виде, то есть фактически считаются стёртыми (так называемая криптографическая санация).
Кроме того, начиная с vSAN 8.0, доступна встроенная функция стирания данных в соответствии со стандартами NIST (например, перезапись нулями или генерация случайных шаблонов). Администратор может запустить безопасное стирание при выведении диска из кластера – vSAN приведёт накопитель в состояние, удовлетворяющее требованиям безопасной утилизации, удалив все остаточные данные. Комбинация шифрования и корректного удаления обеспечивает максимальную степень защиты: даже физически завладев снятым накопителем, злоумышленник не сможет извлечь конфиденциальные данные.
VMware vSAN Encryption Services были разработаны с учётом строгих требований отраслевых стандартов безопасности. Криптографический модуль VMkernel, на котором основано шифрование vSAN, прошёл валидацию FIPS 140-2 (Cryptographic Module Validation Program) ещё в 2017 году. Это означает, что реализация шифрования в гипервизоре проверена независимыми экспертами и отвечает критериям, предъявляемым правительственными организациями США и Канады.
Более того, в 2024 году VMware успешно завершила сертификацию модуля по новому стандарту FIPS 140-3, обеспечив преемственность соответствия более современным требованиям. Для заказчиков из сфер, где необходима сертификация (государственный сектор, финансы, медицина и т.д.), это даёт уверенность, что vSAN может использоваться для хранения чувствительных данных. Отдельно отметим, что vSAN включена в руководства по безопасности DISA STIG для Министерства обороны США, а также поддерживает механизмы двухфакторной аутентификации администраторов (RSA SecurID, CAC) при работе с vCenter — всё это подчёркивает серьёзное внимание VMware к безопасности решения.
Совместимость с функционалом vSAN
Шифрование в vSAN спроектировано так, чтобы быть максимально прозрачным для остальных возможностей хранения. Дедупликация и сжатие полностью совместимы с Data-at-Rest Encryption: благодаря порядку выполнения (сначала дедупликация/сжатие, потом шифрование) эффективность экономии места практически не снижается. Исключение составляет экспериментальная функция глобальной дедупликации в новой архитектуре ESA — на момент запуска vSAN 9.0 одновременное включение глобальной дедупликации и шифрования не поддерживается (ожидается снятие этого ограничения в будущих обновлениях).
Снапшоты и клоны виртуальных машин на зашифрованном vSAN работают штатно: все мгновенные копии хранятся в том же шифрованном виде, и при чтении/записи гипервизор так же прозрачно шифрует их содержимое. vMotion и другие механизмы миграции ВМ также поддерживаются – сама ВМ при миграции может передаваться с шифрованием (функция Encrypted vMotion, независимая от vSAN) или без него, но это не влияет на состояние ее дисков, которые на принимающей стороне всё равно будут записаны на vSAN уже в зашифрованном виде.
Резервное копирование и репликация
vSAN Encryption не накладывает ограничений на работу средств резервного копирования, использующих стандартные API vSphere (такие как VMware VADP) или репликации на уровне ВМ. Данные читаются гипервизором в расшифрованном виде выше уровня хранения, поэтому бэкап-приложения получают их так же, как и с обычного хранилища. При восстановлении или репликации на целевой кластер vSAN, естественно, данные будут записаны с повторным шифрованием под ключи того кластера. Таким образом, процессы защиты и восстановления данных (VDP, SRM, vSphere Replication и пр.) полностью совместимы с зашифрованными датасторами vSAN.
Ограничения и особенности
Поскольку vSAN реализует программное шифрование, аппаратные самошифрующиеся диски (SED) не требуются и официально не поддерживаются в роли средства шифрования на уровне vSAN. Если в серверы установлены SED-накопители, они могут использоваться, но без включения режимов аппаратного шифрования – vSAN в любом случае выполнит шифрование средствами гипервизора. Ещё один момент: при включении vSAN Encryption отключается возможность рентген-просмотра (в веб-клиенте vSAN) содержимого дисков, так как данные на них хранятся в зашифрованном виде. Однако на функциональность управления размещением объектов (Storage Policy) это не влияет. Наконец, стоит учитывать, что шифрование данных несколько повышает требования к процессорным ресурсам на хостах. Практика показывает, что современные CPU справляются с этим отлично, но при проектировании больших нагрузок (вроде VDI или баз данных на all-flash) закладывать небольшой запас по CPU будет не лишним.
VMware vSAN Encryption Services предоставляют мощные средства защиты данных для гиперконвергентной инфраструктуры. Реализовав сквозное шифрование (от диска до сети) на уровне хранения, vSAN позволяет организациям выполнить требования по безопасности без сложных доработок приложений. Среди ключевых преимуществ решения можно отметить:
Всесторонняя защита данных. Даже если злоумышленник получит физический доступ к носителям или перехватит трафик, конфиденциальная информация останется недоступной благодаря сильному шифрованию (AES-256) и раздельным ключам для разных объектов. Это особенно важно для соблюдения стандартов GDPR, PCI-DSS, HIPAA и других.
Прозрачность и совместимость. Шифрование vSAN работает под управлением гипервизора и не требует изменений в виртуальных машинах. Все основные функции vSphere (кластеризация, миграция, бэкап) полностью поддерживаются. Решение не привязано к специфическому оборудованию, а опирается на открытые стандарты (KMIP, TLS), что облегчает интеграцию.
Удобство централизованного управления. Администратор может включить шифрование для всего кластера несколькими кликами – без необходимости настраивать каждую ВМ по отдельности (в отличие от VMcrypt). vCenter предоставляет единый интерфейс для управления ключами, а встроенный NKP ещё больше упрощает старт. При этом разграничение прав доступа гарантирует, что только уполномоченные лица смогут внести изменения в политику шифрования.
Минимальное влияние на производительность. Благодаря оптимизациям (использование AES-NI, эффективные алгоритмы) накладные расходы на шифрование невелики. Особенно в архитектуре ESA шифрование реализовано с учётом высокопроизводительных сценариев и практически не сказывается на IOPS и задержках. Отсутствуют и накладные расходы по ёмкости: включение шифрования не уменьшает полезный объём хранилища и не создаёт дублирования данных.
Гибкость в выборе подхода. vSAN поддерживает как внешние KMS от разных поставщиков (для предприятий с уже выстроенными процессами управления ключами), так и встроенный vSphere Native Key Provider (для простоты и экономии). Администраторы могут ротировать ключи по своему графику, комбинировать или отключать сервисы при необходимости (например, включить только шифрование трафика для удалённого филиала с общим хранилищем).
При внедрении шифрования в vSAN следует учесть несколько моментов: обеспечить высокую доступность сервера KMS (или надёжно сохранить ключ NKP), активировать TPM на хостах для хранения ключей, а также не сочетать шифрование vSAN с шифрованием на уровне ВМ (VM Encryption) без крайней необходимости. Двойное шифрование не повышает безопасность, зато усложняет управление и снижает эффективность дедупликации и сжатия.
В целом же шифрование vSAN значительно повышает уровень безопасности инфраструктуры с минимальными усилиями. Оно даёт организациям уверенность, что данные всегда под надёжной защитой – будь то на дисках или в пути между узлами, сегодня и в будущем, благодаря следованию современным стандартам криптографии FIPS.
В условиях ухода западных вендоров с российского рынка и активного импортозамещения, спрос на отечественные платформы виртуализации значительно вырос. Одним из наиболее ярких и амбициозных проектов в этой области является «Иридиум», решение компании РТ-Иридиум, предназначенное для построения отказоустойчивой и масштабируемой виртуальной инфраструктуры. В июле 2025 года был представлен релиз «Иридиум» 2.0, вобравший в себя широкий набор корпоративных функций.
Архитектура и технологическая база
Платформа «Иридиум» построена на базе гипервизора KVM/QEMU — проверенного временем решения с открытым исходным кодом, которое активно используется и в других коммерческих продуктах (в том числе в ROSA Virtualization и Proxmox). Использование KVM обеспечивает высокую производительность, гибкость, поддержку современных функций виртуализации, а также совместимость с отечественным оборудованием.
Компоненты архитектуры «Иридиум»:
Гипервизор: KVM (работает на Linux, взаимодействует с аппаратной виртуализацией через Intel VT-x/AMD-V).
Управляющая панель: web-интерфейс с ролью диспетчера и оркестратора (аналог vCenter).
VSAN-подобное хранилище: поддержка отказоустойчивого кластера хранения.
Система управления пользователями и политиками безопасности (в том числе LDAP, SSO).
Интеграция с Docker-контейнерами — что делает платформу применимой не только для ВМ, но и для микросервисных архитектур.
Кластеры высокой доступности — объединение до 64 физических узлов с горячей миграцией и автоматическим восстановлением ВМ.
Новые возможности в версии 2.0
Релиз «Иридиум» 2.0 вывел продукт на уровень зрелого корпоративного решения. В числе ключевых новшеств:
HA-кластеры (High Availability) — автоматическое восстановление ВМ при сбое узла.
Горячая и холодная миграция виртуальных машин между узлами.
Встроенное резервное копирование и восстановление.
Поддержка VDI-сценариев (виртуальных рабочих столов).
Контроль доступа и кросс-доменная авторизация.
Новая панель мониторинга с метриками и журналами аудита.
Совместимость с российскими серверами (например, RDW Computers), включая проверку отказоустойчивости.
Сравнение с конкурентами
Характеристика
Иридиум 2.0
ROSA Virtualization
VMware vSphere
Основа гипервизора
KVM/QEMU
KVM/QEMU
Собственный гипервизор ESXi
Интерфейс управления
Web UI, REST API
Web UI (на базе Cockpit)
vCenter
Горячая миграция ВМ
Да
Да
Да
Кластеры высокой доступности
Да
Ограниченно (в Enterprise)
Да (через vSphere HA)
Поддержка VDI
Да
Нет (только через сторонние решения)
Да (через Omnissa)
Репликация и бэкапы
Встроенные
Через сторонние решения
Через Veeam, vSphere Replication
Сертификация ФСТЭК
В процессе получения
Есть (у отдельных сборок)
Нет (нерелевантно для РФ после ухода)
Docker/контейнеры
Да (встроено)
Частично (в экспериментальных сборках)
Через Tanzu (Kubernetes)
Импортозамещение/локализация
Отечественная сборка на базе Open Source
Отечественная сборка на базе Open Source
Нет (не поддерживается в РФ)
Заключение
С выходом версии 2.0 платформа «Иридиум» совершила качественный скачок, превратившись в конкурентоспособную альтернативу западным решениям уровня VMware. Поддержка кластеров высокой доступности, встроенное резервное копирование, интерфейс управления и интеграция с VDI делают продукт особенно привлекательным для корпоративных клиентов, органов власти и критически важных объектов инфраструктуры.
Благодаря открытому гипервизору KVM, российской разработке, масштабируемости и активной интеграции с отечественным «железом», «Иридиум» становится не просто ответом на уход VMware, но полноценным участником новой экосистемы российских ИТ-решений.
VMware Live Recovery (VLR) продолжает обеспечивать надёжную кибер- и информационную устойчивость для VMware Cloud Foundation 9 (VCF), предлагая унифицированную защиту и безопасное восстановление после инцидентов ИБ. Помимо возможностей кибервосстановления, VMware Live Recovery остаётся основой корпоративного оркестратора аварийного восстановления в различных топологиях на базе VCF и включает расширенную репликацию vSphere между сайтами с RPO до одной минуты для поддержки критически важных приложений. VMware Live Recovery также интегрирован с функциями защиты данных хранилища VMware vSAN ESA. Всё более глубокая интеграция между VLR и основными компонентами VCF, такими как vSAN, выделяет решение на фоне конкурентов и усиливает ценность единой платформы для клиентов.
С последним релизом VMware Cloud Foundation 9 в решение VMware Live Recovery были добавлены следующие ключевые улучшения:
VLR Appliance – упрощённое развертывание и управление сервисами
Интеграция с VMware Cloud Foundation – улучшенный доступ к данным защиты
Улучшенная интеграция Protection Group и Recovery Plan с защитой данных vSAN
Кибервосстановление – поддержка сценариев на стороне заказчика, повышение суверенитета данных
VLR Appliance – упрощённое развертывание и управление сервисами
Теперь клиенты могут управлять всеми операциями восстановления с помощью одного виртуального модуля VLR. Это обновление позволяет использовать единую, комбинированную, простую в установке и управлении виртуальную машину, упрощающую управление жизненным циклом решения для нескольких сервисов защиты.
В новом объединённом устройстве VLR консолидации подверглись следующие сервисы защиты и восстановления:
Расширенная репликация между сайтами на базе vSphere
Снапшоты на базе vSAN на заданных (исходном/целевом) сайтах vSAN ESA
Автоматизация и оркестрация Site Recovery
Этот релиз VLR Appliance доступен всем клиентам с подпиской VLR, а также владельцам бессрочных лицензий SRM с действующей поддержкой SnS или временной подпиской. Новый модуль можно установить на сервер vCenter для объединения ранее установленных компонентов, как показано ниже:
Информация по развертыванию
Виртуальный модуль VLR Appliance поставляется в двух вариантах:
Основной объединённый модуль.
Дополнительный модуль службы восстановления для расширенных сценариев оркестрации аварийного восстановления, например, при использовании общих сайтов восстановления.
Важно отметить, что новый модуль VLR будет единственным вариантом, совместимым с VCF, но при этом сохраняет обратную совместимость с более старыми версиями ESX и vCenter (8.0 U3b+, 8.0 U2d+), чтобы обеспечить корректную межсайтовую работу и совместимость при переходе клиентов на новую платформу VCF. Как всегда, рекомендуется использовать инструмент совместимости продуктов VMware перед обновлениями — в данном случае, чтобы сравнить компоненты VMware Live Site Recovery и VMware Cloud Foundation.
Расширенная репликация vSphere теперь включена в унифицированную модель развертывания VLR и обеспечивает более масштабируемую и эффективную репликацию с возможностью RPO до одной минуты.
Важно: расширенная репликация vSphere теперь является конфигурацией по умолчанию и единственно поддерживаемой для репликации между сайтами. Для сайтов, использующих старые версии vSphere Replication, перед установкой нового модуля VLR потребуется обновление до Enhanced vSphere Replication. Подробности об обновлении см. в документации. Если используется репликация на уровне СХД (array-based replication), необходимо установить SRA и array-менеджеры на новое устройство VLR и настроить их отдельно. Для дополнительной информации о выпуске этого VLR Appliance см. документацию по VMware Live Recovery Appliance.
Интеграция с VMware Cloud Foundation – лучший доступ к данным защиты
Платформа VMware Cloud Foundation поддерживает одновременную работу как традиционных виртуальных машин, так и модернизированных рабочих нагрузок. Совместимость VMware Live Recovery была обновлена, особенно в части свойств виртуальных машин для поддержки переключения (failover) и возврата (failback). Подробности о поддержке защищённых, управляемых сервисами ВМ доступны в документации.
Теперь VLR интегрирован в консоль операций VCF, что позволяет клиентам отслеживать все развертывания защиты данных VCF из единого интерфейса. Эта интеграция охватывает кибервосстановление, аварийное восстановление, репликацию vSphere, репликацию vSAN и удалённые снапшоты (remote snapshots).
Панель Data Protection & Recovery в VCF Operations для VMware Live Recovery предоставляет критически важную информацию в одном месте. Пользователи могут быстро оценить:
Сколько виртуальных машин защищено и подлежит восстановлению.
Какие ВМ в данный момент не защищены.
Ёмкость защищённого хранилища и возможности её масштабирования под нужды ИТ-инфраструктуры.
Для более глубокого анализа можно установить VLR и VR Management Packs, чтобы получить доступ к предустановленным дэшбордам. Пример дэшборда верхнего уровня:
Улучшенная интеграция групп защиты (Protection Groups) и планов восстановления (Recovery Plans) с защитой данных vSAN
Устройство VLR Appliance поддерживает службы Data Protection Snapshot Management Services для vSAN ESA и обеспечивает более глубокую интеграцию в оркестрационную платформу VMware Live Recovery. Для хранилищ на базе vSAN ESA благодаря интеграции с VLR теперь доступны три ключевые функции:
Чтобы упростить защиту виртуальных машин, конфигурации групп защиты (Protection Groups) автоматически обнаруживаются и доступны как через интерфейс vSAN Data Protection UI, так и через VMware Live Site Recovery, что существенно упрощает администрирование защиты и восстановления в масштабах всей инфраструктуры предприятия.
Кибервосстановление – поддержка локальных сценариев и повышение суверенитета данных
С этим релизом VCF и новой версией VLR клиенты могут использовать утверждённую VMware архитектуру (VMware Validated Solution), реализованную как драфт для версии 9.0, для создания локальной зоны кибервосстановления (clean room). Эта архитектура использует:
Домен рабочих нагрузок VCF как изолированную clean room.
Кластер хранения vSAN ESA как защищённое кибер-хранилище (cyber data vault).
vDefend для сетевой изоляции.
VMware Live Recovery для оркестрации процессов восстановления.
Теперь организации, которым необходимо соблюдать требования к конфиденциальности данных или территориальной принадлежности (data residency), могут обеспечивать суверенитет данных, не передавая их в публичное облако, а размещая инфраструктуру восстановления в локальной среде VCF clean room.
Общая архитектура такого сценария показана на схеме ниже:
Последний релиз VMware Cloud Foundation (VCF) и обновления VMware Live Recovery (VLR) включают важные усовершенствования, направленные на удовлетворение современных требований ИТ-организаций к защите и восстановлению данных. Чтобы узнать больше о глубокой интеграции всех средств защиты, упрощённых методах развертывания и управления, а также расширенных возможностях сценариев восстановления — ознакомьтесь с материалами по следующим ссылкам: VMware Live Recovery и документация по VLR.
Таги: VMware, Live Recovery, Update, VCF, Security, Replication
Если вы знакомы с PowerCLI, вам наверняка нравится, как легко с его помощью выполнять обычные административные задачи в экосистеме VMware. Недавно компания рассказала о совершенно новом уровне возможностей. Он предоставляет прямой доступ ко всем API-методам - это пакет PowerCLI SDK. Он уже включён в вашу установку PowerCLI — дополнительных скачиваний или настройки не требуется.
Что такое PowerCLI SDK?
Фоеймворк PowerCLI предлагает высокоуровневые командлеты. Кроме того, он включает автоматически генерируемые SDK-модули для многих основных продуктов VMware, таких как vSphere, NSX, SRM и VMware Cloud Foundation (VCF). Эти SDK дают точный доступ к API через PowerShell, позволяя создавать пользовательские автоматизации низкого уровня.
Чтобы увидеть доступные SDK в вашей среде, выполните команду:
Get-Module -ListAvailable -Name “VMware.SDK*”
Вы увидите вывод наподобие:
Начало работы: изучение VMware Cloud Foundation с помощью SDK
Давайте рассмотрим реальный пример использования модуля VMware.Sdk.Vcf.SddcManager. Этот модуль предоставляет доступ к полному API VMware Cloud Foundation (VCF) через PowerShell.
Загрузка модуля
Import-Module VMware.Sdk.Vcf.SddcManager
Подключение к VCF. Подобно Connect-VIServer, SDK имеет собственную команду подключения:
Таким образом, вы получаете структурированные данные о доменах нагрузки без необходимости писать API-обёртки и вручную управлять заголовками аутентификации.
Встроенная помощь и документация
SDK-командлеты включают полную поддержку справки по всем аспектам вызываемых API:
Get-Help Invoke-VcfGetDomains -Full
Здесь вы найдёте примеры использования, описание параметров и ссылки на онлайн-документацию API. Это существенно облегчает процесс обучения и разработки.
Поддерживаемые продукты
SDK-модули доступны для многих продуктов VMware, включая:
VMware Cloud Foundation (SDDC Manager)
vSphere
NSX-T
Site Recovery Manager (SRM)
vSphere Replication
Важно понимать, что все они автоматически включаются в последние версии фреймворка PowerCLI.
Итог
PowerCLI SDK предоставляет полный доступ к API продуктов VMware с помощью привычного синтаксиса PowerShell. Вы получаете полный контроль при создании сложных автоматизаций и можете интегрировать свои сценарии в конвейеры CI/CD без необходимости выходить из терминала. Вы также можете комбинировать высокоуровневые командлеты PowerCLI с операциями SDK, чтобы получить максимальную эффективность.
Object First — это компания, основанная Ратмиром Тимашевым, одним из легендарных сооснователей Veeam Software. После того как Veeam был продан инвестиционной компании Insight Partners за $5 млрд в 2020 году, Тимашев отошел от операционного управления компанией, но остался в ИТ-индустрии. Его новым проектом стала Object First, цель которой — предложить максимально простое, защищенное и производительное решение для хранения резервных копий, оптимизированное под решения Veeam.
Цели и философия Object First
Object First была создана с четким пониманием болевых точек ИТ-отделов: сложность настройки хранилищ, высокая стоимость масштабируемых решений и растущие угрозы кибератак, в том числе программ-вымогателей. Команда Object First стремится решить эти проблемы с помощью подхода "Secure by Design" и глубокой интеграции с Veeam Backup and Replication.
Что такое Ootbi?
Флагманский продукт Object First называется Ootbi ("Out-of-the-box immutability") — это on-premise объектное хранилище, специально созданное для Veeam. Основные технические особенности Ootbi:
Готовность к работе "из коробки": решение поставляется в виде готового устройства, не требующего глубокой предварительной настройки.
Поддержка объектного хранилища S3: Ootbi работает по протоколу S3 и полностью совместим с Veeam Backup & Replication.
Неизменяемость данных (immutability): встроенная защита от программ-вымогателей (Ransomware). Используются политики WORM (Write Once, Read Many), гарантирующие, что резервные копии не могут быть удалены или изменены в течение заданного периода (даже с административными привилегиями).
Интеграция с Veeam через Scale-Out Backup Repository (SOBR): Ootbi можно использовать как capacity tier, обеспечивая гибкое и масштабируемое резервное копирование.
Безопасность и упрощенное администрирование: не требуется root-доступ или отдельные операционные системы. Решение изолировано и минимизирует человеческий фактор.
Аппаратная архитектура
На данный момент Ootbi представляет собой масштабируемую кластерную систему из 2-4 узлов:
Каждый узел содержит вычислительные ресурсы и локальное хранилище (HDD и SSD для кэширования).
Используется распределённая файловая система, обеспечивающая отказоустойчивость и высокую доступность.
Производительность: до 4 ГБ/сек совокупной пропускной способности, до 1 ПБ эффективного объема хранения с учетом дедупликации и компрессии на стороне Veeam.
Преимущества для клиентов
Минимизация риска потери данных благодаря immutability и встроенной защите.
Снижение TCO (total cost of ownership) за счет простоты управления и отказа от сложных инфраструктур.
Быстрое развёртывание: установка и настройка возможна за считанные часы.
Отсутствие необходимости в публичном облаке, что важно для компаний с повышенными требованиями к безопасности и локализации данных.
Object First предлагает уникальное, строго специализированное решение для клиентов Veeam, закрывающее потребности в безопасном и удобном хранении резервных копий. Подход компании отражает философию ее основателя — создавать простые и эффективные продукты, фокусируясь на ключевых болевых точках рынка. Ootbi становится привлекательным выбором для компаний, стремящихся к максимальной защищенности своих данных без лишней сложности и затрат.
На прошедшей недавно конференции VeeamON 2025 было рассказано о скором выходе новой версии Veeam Backup & Replication 13, в которой будут представлены новые функции, направленные на повышение доступности (High Availability, HA), что позволяет компаниям поддерживать бесперебойную работу и защищать критически важные данные даже в случае непредвиденных ситуаций. Эта возможность уже давно запрашивалась пользователями, и вот, наконец, она будет реализована в производственной среде.
Помимо высокой доступности, Veeam Backup & Replication v13 предложит впечатляющие возможности, такие как развертывание сервера управления, хранилища, прокси и других компонентов напрямую из Veeam Software Appliance, мгновенное восстановление в Microsoft Azure, расширенное управление доступом на основе ролей (RBAC), а также множество других улучшений.
В Veeam Backup & Replication v13 возможности HA были расширены за счёт внедрения резервного управляющего сервера, готового к моментальному переключению при необходимости. В фоновом режиме репликация базы данных PostgreSQL обеспечивает постоянное дублирование всех конфигурационных данных, что гарантирует готовность системы к любым сбоям. При этом механизм репликации кэша, встроенный в базу данных, непрерывно передаёт данные на резервный сервер, обеспечивая его синхронность с основным узлом. Такая проактивная настройка устраняет время ожидания в случае аварии — резервная машина Veeam Backup & Replication полностью готова к работе и может быть активирована при необходимости.
На первом этапе функция HA будет доступна только для Veeam Backup & Replication на платформе Linux (дистрибутив основан на Rocky Linux). Процесс переключения выполняется вручную и по требованию — администраторы могут инициировать его в нужный момент, так как автоматические триггеры пока не предусмотрены. Архитектура реализована по схеме "активный-пассивный" с двумя узлами, с акцентом на надёжность.
Настройка сервера
После установки Veeam Backup & Replication v13 с помощью Veeam Software Appliance (в формате .ova или .iso), необходимо выполнить несколько базовых шагов конфигурации самого сервера. В этот процесс входят следующие ключевые этапы:
Настройка имени: присвойте виртуальному модулю понятное и информативное имя для его простой идентификации в инфраструктуре.
Сетевые настройки: установите сетевые параметры для надёжной связи с другими компонентами и резервным сервером.
Настройка NTP: укажите сервер синхронизации времени (Network Time Protocol), чтобы обеспечить точное совпадение времени на всех системах. Это критически важно, например, для проверки одноразовых паролей (OTP).
Пароль в соответствии с DISA STIG: создайте безопасный пароль, соответствующий требованиям DISA STIG, чтобы усилить защиту сервера Veeam Backup & Replication.
OTP для администратора и офицера безопасности Veeam: сгенерируйте и настройте одноразовые пароли для ролей администратора и офицера безопасности (Security Officer). Несмотря на то, что для корректной работы OTP требуется точное время, доступ к интернету для их проверки не нужен, что позволяет использовать систему в изолированных средах.
Настройка кластера
Создание кластера и настройка сети - укажите сетевые параметры для надёжной связи с другими компонентами и резервным сервером.
Задайте сетевые параметры основного и резервного узлов. Убедитесь, что оба узла кластера находятся в одной IP-подсети — на этапе бета-тестирования это обязательное условие.
После этого начнется процесс создания и конфигурации кластера.
Если основной узел не отвечает, вы можете инициировать операцию переключения (failover), чтобы ввести в работу резервный узел.
Важным преимуществом такого подхода является то, что нет необходимости импортировать резервную копию конфигурации, заново создавать задания, импортировать бэкапы или повторно вводить учётные данные — Veeam Backup & Replication продолжает работать без перебоев. Мы ещё увидим, какие дополнительные возможности появятся в финальном релизе, запланированном на конец этого года. Возможно, будут добавлены новые функции, но даже на текущем этапе это крайне полезная возможность, которая экономит массу времени в аварийной ситуации.
Хотя процесс переключения не автоматизирован и должен запускаться вручную авторизованным пользователем, появление команд PowerShell в будущих версиях откроет возможность создания и интеграции собственной логики автоматизации — например, с использованием узла-наблюдателя (witness node).
Компания Veeam выпустила исправление для критической уязвимости удалённого выполнения кода (RCE) под идентификатором CVE-2025-23120, обнаруженной в программном обеспечении Veeam Backup & Replication. Уязвимость затрагивает развертывания, где сервер резервного копирования работает в составе домена AD.
Информация об уязвимости была опубликована около недели назад - она затрагивает версию Veeam Backup & Replication 12.3.0.310 и все более ранние сборки 12-й версии. Компания устранила проблему в версии 12.3.1 (сборка 12.3.1.1139), которая была выпущена несколько дней назад.
Согласно техническому отчёту от компании watchTowr Labs, которая обнаружила данную ошибку, CVE-2025-23120 представляет собой уязвимость десериализации в .NET-классах Veeam.Backup.EsxManager.xmlFrameworkDs и Veeam.Backup.Core.BackupSummary.
Уязвимость десериализации возникает, когда приложение неправильно обрабатывает сериализованные данные, позволяя злоумышленникам внедрять вредоносные объекты («гаджеты»), способные запускать опасный код.
В прошлом году компания Veeam исправляла похожую уязвимость удалённого выполнения кода (RCE), обнаруженную исследователем Флорианом Хаузером. Чтобы устранить проблему, Veeam внедрила чёрный список известных классов или объектов, которые могли использоваться для атак.
Однако специалисты компании watchTowr смогли найти другую цепочку гаджетов, не включённую в чёрный список, что позволило им снова добиться удалённого выполнения кода.
«В общем, вы, наверное, уже догадались, к чему всё идёт — похоже, что Veeam, несмотря на то, что остаётся любимой игрушкой группировок, распространяющих программы-вымогатели, не усвоила урок после исследования, опубликованного Frycos. Как вы уже поняли — они вновь исправили проблемы десериализации, просто добавив новые записи в свой чёрный список десериализации.»
Хорошая новость в том, что эта уязвимость затрагивает только те установки Veeam Backup & Replication, которые присоединены к домену. Плохая — любой доменный пользователь способен эксплуатировать данную уязвимость, что делает её особенно опасной в таких конфигурациях.
К сожалению, многие компании всё ещё подключают свои серверы Veeam к доменам Windows, игнорируя давно рекомендованные разработчиком правила безопасности.
Представители группировок, использующих программы-вымогатели, ранее уже сообщали, что серверы Veeam Backup & Replication всегда являются их целью, так как обеспечивают удобный способ похищать данные и препятствовать восстановлению систем, удаляя резервные копии. Эта новая уязвимость ещё больше повышает привлекательность серверов Veeam для злоумышленных группировок, так как она значительно упрощает взлом таких серверов.
Несмотря на отсутствие на текущий момент сообщений о реальных случаях эксплуатации уязвимости, watchTowr уже раскрыла достаточное количество технических деталей, поэтому в ближайшее время вполне вероятно появление общедоступного эксплойта (PoC). Компании, использующие Veeam Backup & Replication, должны максимально оперативно обновиться до версии 12.3.1.
Также, учитывая пристальное внимание группировок-вымогателей к данному приложению, настоятельно рекомендуется пересмотреть лучшие практики безопасности Veeam Backup и отключить серверы от домена.
На просторах обнаружился интересный сайт VeeamClick.be, предлагающий интерактивные демонстрации продуктов Veeam, что позволяет пользователям ознакомиться с функциональными возможностями решений компании в режиме онлайн. Сайт создан и поддерживается Стийном Маривоетом (Stijn Marivoet) и предоставляет бесплатный доступ к своим материалам.
Основные разделы сайта:
Veeam Backup and Replication: в этом разделе представлены как базовые, так и расширенные операции, компоненты архитектуры продукта и функции, ориентированные на безопасность.
M365 Backup: здесь можно найти демонстрации по резервному копированию Microsoft 365 с использованием Veeam Backup for M365 и Veeam Data Cloud.
Veeam Orchestrator: интерактивные материалы по оркестрации процессов резервного копирования и восстановления.
Veeam Backup for Salesforce: демонстрации, показывающие возможности резервного копирования данных Salesforce.
K10: материалы, связанные с инфраструктурой Kubernetes и решениями Veeam для контейнеризированных приложений.
Каждый из этих разделов содержит списки потенциальных операций и функций, доступных для изучения. Если у пользователей есть специфические запросы, они могут связаться с администратором сайта для получения дополнительной информации.
VMware Cloud Foundation (VCF) — это гибридная облачная платформа, которая позволяет запускать приложения и рабочие нагрузки в частном или публичном облаке. VCF — отличный вариант для предприятий, стремящихся модернизировать свою ИТ-инфраструктуру.
Существует несколько способов переноса рабочих нагрузок в VCF. В этой заметке мы рассмотрим три различных варианта:
Решение VMware HCX
Утилита VCF Import Tool
Средство комплексной DR-защиты виртуальных сред VMware Site Recovery
Дорожная карта миграции в VCF обычно включает следующие этапы:
Оценка (Assessment): на этом этапе вы анализируете свою текущую ИТ-среду и определяете оптимальный способ миграции рабочих нагрузок в VCF.
Планирование (Planning): вы разрабатываете детальный план миграции.
Миграция (Migration): осуществляется перенос рабочих нагрузок в VCF.
Оптимизация (Optimization): в заключение, вы оптимизируете среду VCF, чтобы обеспечить стабильную и эффективную работу рабочих нагрузок.
VMware HCX (Hybrid Cloud Extension)
VMware HCX — это продукт, который позволяет переносить виртуальные машины между различными средами VMware. В том числе, он поддерживает миграцию виртуальных машин из локальных сред vSphere в облако VCF (также поддерживаются платформы Hyper-V или KVM на источнике).
HCX — отличный вариант для предприятий, которым необходимо перенести большое количество виртуальных машин с минимальным временем простоя.
VMware HCX позволяет создать единую среду между онпремизным датацентром и облачным на основе архитектуры VMware Cloud Foundation (VCF), где работают средства по обеспечению катастрофоустойчивости рабочих нагрузок VMware Live Site Recovery.
HCX предоставляет возможность миграции виртуальных машин и приложений между различными видами облаков по принципу Any2Any. С точки зрения виртуальной машины, ее ОС и приложений, HCX выступает уровнем абстракции, который представляет машине единую гибридную среду в которой находятся все локальные и облачные ресурсы (infrastructure hybridity). Это дает возможность машинам перемещаться между датацентрами, не требуя реконфигурации самих ВМ или инфраструктуры.
VMware Cloud Foundation (VCF) Import Tool
В обновлении платформы VMware Cloud Foundation 5.2 был представлен новый инструмент командной строки (CLI), называемый VCF Import Tool, который предназначен для преобразования или импорта существующих сред vSphere, которые в настоящее время не управляются менеджером SDDC, в частное облако VMware Cloud Foundation. Вы можете ознакомиться с демонстрацией работы инструмента импорта VCF в этом 6-минутном видео.
Инструмент импорта VCF позволяет клиентам ускорить переход на современное частное облако, предоставляя возможность быстро внедрить Cloud Foundation непосредственно в существующую инфраструктуру vSphere. Нет необходимости приобретать новое оборудование, проходить сложные этапы развертывания или вручную переносить рабочие нагрузки. Вы просто развертываете менеджер SDDC на существующем кластере vSphere и используете инструмент импорта для преобразования его в частное облако Cloud Foundation.
Импорт вашей существующей инфраструктуры vSphere в облако VCF происходит без сбоев, поскольку это прозрачно для работающих рабочих нагрузок. В общих чертах, процесс включает сканирование vCenter для обеспечения совместимости с VCF, а затем регистрацию сервера vCenter и его связанного инвентаря в менеджере SDDC. Зарегистрированные экземпляры сервера vCenter становятся доменами рабочих нагрузок VCF, которые можно централизованно управлять и обновлять через менеджер SDDC как часть облака VMware. После добавления в инвентарь Cloud Foundation все доступные операции менеджера SDDC становятся доступны для управления преобразованным или импортированным доменом. Это включает в себя расширение доменов путем добавления новых хостов и кластеров, а также применение обновлений программного обеспечения.
VMware Live Site Recovery
VMware Live Site Recovery (бывший VMware Site Recover, SRM) — это решение для аварийного восстановления (DR), которое также можно использовать для миграции виртуальных машин в среду VCF как часть исполнения DR-плана. Оно является частью комплексного предложения VMware Live Recovery.
Этот вариант подходит для предприятий, которым необходимо защитить свои виртуальные машины от аварийных ситуаций, таких как отключение электроэнергии или пожары, за счет исполнения планов аварийного восстановления в облако VCF.
Последняя версия документации по этому продукту находится здесь.
В последней версии Veeam Backup and Replication 12.2 компания Veeam добавила еще один модуль для резервного копирования баз данных - Veeam Explorer for MongoDB.
С помощью Veeam Explorer для MongoDB можно выполнять детальное восстановление одной или нескольких коллекций MongoDB, а также баз данных, или восстанавливать всю инстанцию MongoDB целиком.
Требования для резервного копирования MongoDB:
MongoDB 7.0, MongoDB 6.0 или MongoDB 5.0.
Поддерживаются только 64-битные версии ОС для сервера базы данных: Debian 9 или новее, RHEL 6.2 или новее, CentOS 6.2 или новее, Oracle Linux 6.2 или новее, Rocky 8.0 или новее, Alma 8.0 или новее, SLES 12 SP4 – SP5, SLES 15 SP1 – SP5, Ubuntu 16.04 или новее.
Нативная поддержка в Veeam 12.2 означает, что вы выполняете резервное копирование не только базовой ОС Linux (с помощью Linux-агента), но и самой MongoDB. Восстановлением можно управлять через стандартный интерфейс Veeam Explorer, как обычно для такого типа резервных копий на уровне приложений.
Когда вы впервые выполняете повторное сканирование набора реплик MongoDB (группы экземпляров, которые поддерживают один и тот же набор данных), Veeam Backup & Replication разворачивает следующие компоненты Veeam на каждом компьютере, где обнаружен основной демон MongoDB (mongod):
Служба Veeam Transport Service отвечает за соединение между Veeam Backup & Replication и компонентами Veeam, работающими на компьютере с MongoDB. Агент Veeam Mongo Agent — это компонент, который собирает информацию об иерархии базы данных с компьютера и взаимодействует с демоном mongo для операций резервного копирования. Агент Veeam для Linux — это компонент, который выполняет резервное копирование томов с данными MongoDB и отправляет резервную копию в целевое хранилище.
Теперь за счет Veeam Explorer для MongoDB вы получаете следующие преимущества:
Усиленная защита данных: благодаря поддержке MongoDB в Veeam ИТ-администраторы могут быть уверены, что их данные защищены от сбоев оборудования, человеческих ошибок и киберугроз.
Гибкие варианты резервного копирования: новая функция позволяет выполнять как резервное копирование на уровне образа, так и на уровне приложений, предоставляя администраторам гибкость выбора наиболее подходящего подхода для их нужд.
Бесшовный процесс восстановления: в случае потери данных мощные возможности восстановления Veeam позволяют быстро и эффективно восстановить данные, минимизируя время простоя и обеспечивая непрерывность бизнеса.
Масштабируемость: решение Veeam разработано с учетом масштабирования вместе с развертыванием MongoDB, что позволяет учитывать растущие объемы данных и сложные окружения.
Более подробно о Veeam Explorer для MongoDB с описанием процессов резервного копирования и восстановления можно почитать вот в этом документе.
Недавно компания Veeam представила второй релиз бесплатного решения Veeam Hardened Repository ISO. Первая версия была выпущена еще в июне 2023 года, сейчас вышло ее обновление. Veeam Hardened ISO Repository (VHR) предназначен для облегчения создания защищённого Linux-репозитория для решения Veeam Backup and Replication, так как не каждый администратор имеет достаточный опыт работы с Linux для эффективной защиты операционной системы. Veeam предлагает инструмент, который позволяет сделать это быстро и легко. Скачивание доступно бесплатно, но поскольку это технологическое превью, этот инструмент пока не следует использовать в производственных средах. ISO позволит вам создать безопасный репозиторий с функцией неизменяемости данных (immutability).
Преимущества ISO
Главное преимущество ISO заключается в том, что вам не нужно выполнять дополнительные настройки или запускать скрипты (система уже защищена благодаря специальному установщику).
В системе нет пользователя root.
Благодаря использованию Rocky Linux в качестве основы, вы получаете 10 лет поддержки для ОС.
После выхода официальной версии вы также получите поддержку от Veeam.
Требования
Оборудование, поддерживаемое RedHat (для развертывания в производственной рекомендуется физический сервер, для лабораторных условий возможна виртуальная машина), сам ISO основан на Rocky Linux.
Те же требования к CPU и RAM, что и для Linux-репозиториев.
2 диска с объёмом не менее 100 ГБ каждый.
Поддерживается только внутреннее хранилище или напрямую подключаемое хранилище с аппаратным RAID-контроллером и кэшем записи.
UEFI должен быть активирован.
Минимальная версия Veeam - V12.2.
Veeam Hardened ISO — это загрузочный ISO-образ, разработанный для упрощения настройки Veeam Hardened Repositories. Этот новый метод доставки устраняет необходимость в глубоком знании Linux, делая его доступным для более широкой аудитории. Развертывая защищённые репозитории через этот ISO, пользователи могут значительно снизить затраты на постоянное управление и повысить безопасность своей инфраструктуры резервного копирования.
Одной из ключевых особенностей Veeam Hardened ISO является возможность создания безопасного и неизменяемого репозитория для резервного копирования. Это означает, что после записи данных в репозиторий их нельзя изменить или удалить, что защищает их от атак программ-вымогателей и других вредоносных действий. Такой уровень безопасности крайне важен в современном мире, где утечки данных и кибератаки становятся всё более частыми.
Вам предоставляется преднастроенная операционная система с автоматически применённым профилем безопасности DISA STIG. Также доступен инструмент настройки защищённого репозитория (Hardened Repository Configurator Tool), который упрощает настройку сети и позволяет изменить такие параметры, как настройки HTTP-прокси, имя хоста, пароль для пользователя vhradmin, временное включение SSH, обновление ОС и компонентов Veeam, сброс защиты от смещения времени, а также выполнять простые действия, такие как вход в систему, перезагрузка или выключение.
Ключевые особенности Veeam Hardened ISO
Упрощённое развертывание — Veeam Hardened ISO значительно упрощает процесс развертывания, позволяя пользователям настраивать защищённые репозитории без необходимости глубокого знания Linux. Эта простота в использовании гарантирует, что даже пользователи с ограниченными техническими навыками могут воспользоваться передовыми возможностями защиты данных от Veeam.
Повышенная безопасность — неизменяемость Veeam Hardened Repository гарантирует, что данные резервного копирования остаются защищёнными и не могут быть изменены. Это особенно важно в условиях атак программ-вымогателей, где целостность данных резервного копирования играет ключевую роль.
Экономическая эффективность — благодаря снижению потребности в постоянном управлении и обслуживании, Veeam Hardened ISO помогает организациям экономить на операционных расходах. Такая эффективность делает решение привлекательным для компаний любого размера.
Обратная связь сообщества — поскольку Veeam Hardened ISO на данный момент находится в статусе Community Preview, пользователи могут предоставлять обратную связь и вносить свой вклад в его развитие. Такой совместный подход помогает создать продукт, который будет соответствовать потребностям и ожиданиям сообщества Veeam.
Скачать Veeam Hardened Repository ISO можно по этой ссылке. Дефолтный пароль - VHRISO.
Veeam использует интеллектуальный анализ данных во всей своей платформе, чтобы защищать ваши критические данные, обеспечивать их целостность и помогать организациям становиться более эффективными. Veeam предоставляет не только возможности резервного копирования данных, но и видимость вашей системы резервного копирования и виртуальной среды через мониторинг и отчётность в Veeam Data Platform Advanced. Благодаря этому вы можете выявлять проблемы, которые могут снижать производительность виртуальных машин или нарушать операции резервного копирования и препятствовать восстановлению данных.
Veeam Intelligent Diagnostics, функция, входящая в состав Veeam ONE (часть пакета Veeam Data Platform Advanced), позволяет автоматически выявлять известные проблемы в конфигурации и производительности инфраструктуры резервного копирования. Активировав эту функциональность через Veeam ONE, вы получаете уведомления об общих ошибках, что позволяет вам быстрее их устранять с помощью статей из базы знаний и предлагаемых решений, что снижает риски в вашей среде и гарантирует готовность к защите или восстановлению данных в любой момент.
Сигнатуры Veeam Intelligent Diagnostics
У Veeam более 550 000 клиентов, что, если задуматься, является огромным числом. Клиенты Veeam бывают самых разных размеров и работают в различных областях. От технологических компаний до медицинских организаций, нефтегазовых компаний и образовательных учреждений — Veeam защищает огромный объём данных своих клиентов.
Клиенты используют продукты по-разному, и, изучая различные случаи поддержки, Veeam узнает много нового о типичных проблемах, с которыми они сталкиваются. Veeam создает новые сигнатуры Veeam Intelligent Diagnostics на основе того, что наблюдают сотрудники компании, например, общие ошибки конфигурации или проблемы, которые возникают только в очень специфических условиях, о которых клиент даже не мог бы подумать, как, например, проблема с производительностью.
С помощью Veeam Intelligent Diagnostics можно использовать уроки, извлечённые из этих сред, чтобы снизить риски для всех клиентов.
Как VID анализирует виртуальные среды
С помощью простого агента, установленного на сервер Veeam Backup & Replication через Veeam ONE, состояние вашей среды Veeam анализируется безопасно, при этом вы полностью контролируете свои данные. Установка на серверы Veeam выполняется в один клик (если это не было сделано при подключении к среде Veeam ONE).
При этом никакие ваши данные никогда не отправляются на серверы Veeam. Вместо этого Veeam ONE просто загружает новые сигнатуры Veeam Intelligent Diagnostics с серверов Veeam, а агент, установленный на сервере Veeam, выполняет анализ. Клиенты, использующие Veeam Data Platform Advanced и Premium, могут в любое время проверить наличие новых сигнатур через Veeam ONE Data Protection View или загрузить их напрямую с веб-сайта Veeam и импортировать на сервер Veeam ONE.
Анализ логов VID может быть настроен на ежедневный запуск, а также выполняться по запросу в любое время. На самом деле, не существует более простого способа для принятия проактивных мер по защите вашей среды Veeam Backup & Replication.
Исправляйте проблемы до того, как они повлекут последствия
Сигнатуры VID обновляются дважды в месяц и содержат множество улучшений. Помимо новых определений для обнаружения проблем, с которыми могут столкнуться клиенты Veeam, обновления также включают новые возможности и улучшения самого диагностического механизма.
Если обнаружена проблема, клиенты получают уведомления через алармы в Veeam ONE с важной информацией, которая упрощает процесс устранения проблемы. Давайте рассмотрим одну из последних сигнатур VID.
Этот пример касается задач резервного копирования на ленту, он идентифицирует причину срабатывания аларма и предлагает способы её устранения. В этом случае можно увидеть, что обновление до последней версии Veeam Backup and Replication может помочь решить проблему. Если это не помогает, вам предоставляется номер тикета Veeam Intelligent Diagnostics, чтобы упростить процесс поддержки и получить частное исправление.
В данном случае Veeam Intelligent Diagnostics предоставил правильное решение, которое требует обновления. Просто подождите установки обновления 15-20 минут, и вы больше не столкнетесь с этой проблемой. Это отличный пример того, как Veeam помогает своим клиентам действительно понять, что происходит в их среде, и избежать возможных обращений в службу поддержки.
Все клиенты Veeam Data Platform могут снизить риски в своих средах, используя Veeam Intelligent Diagnostics, и в индустрии нет ничего подобного. Veeam безопасно обрабатывает информацию из логов вашей среды непосредственно на ваших серверах Veeam. Ваши данные никогда не отправляются на сервера Veeam или куда-либо ещё.
Опираясь на опыт более чем 550 000 клиентов, Veeam постоянно обновляет определения VID и отправляет их при возникновении новых проблем и рисков, помогая клиентам устранять сложности до того, как они повлекут серьезные последствия.
Если вы уже используете Veeam Data Platform Advanced или Premium, уделите несколько минут, чтобы убедиться, что у вас установлен агент Veeam ONE. Затем вы сможете просмотреть сигнатуры Veeam Intelligent Diagnostics, зайдя в раздел Intelligent Diagnostics в секции Backup & Replication представления Alarm Management.
Если вы ещё не используете Veeam Data Platform Advanced или Premium, вы можете загрузить бесплатную пробную версию на 30 дней, чтобы протестировать функции Veeam Intelligent Diagnostics.
Это средство было сделано энтузиастами (Raphael Schitz и Frederic Martin) в качестве альтернативы платным продуктам для мониторинга серверов ESXi и виртуальных машин. Представления SexiPanels для большого числа метрик в различных разрезах есть не только для VMware vSphere и vSAN, но и для ОС Windows и FreeNAS.
Давайте посмотрим на новые возможности двух недавних релизов:
Релиз Lighthouse Point (0.99k) от 7 октября 2024
VMware Snapshot Inventory
Начиная с версии SexiGraf 0.99h, панель мониторинга «VI Offline Inventory» заменена на VMware Inventory с инвентаризацией ВМ, хостов и хранилищ данных (вскоре добавятся портгруппы и другие элементы). Эти новые панели имеют расширенные возможности фильтрации и значительно лучше подходят для крупных инфраструктур (например, с более чем 50 000 виртуальных машин). Это похоже на извлечение данных из RVtools, которое всегда отображается и актуально.
В релизе v0.99k появилось представление VM Snapshot Inventory:
Улучшения "Cluster health score" для VMware vSAN 8
Вместо того чтобы бесконечно нажимать на кнопку обновления на вкладке «Resyncing Components» в WebClient, начиная с версии SexiGraf 0.99b разработчики добавили панель мониторинга vSAN Resync:
Shell In A Box
В версии SexiGraf 0.99k разработчики добавили отдельный дэшборд Shell In A Box за обратным прокси-сервером, чтобы снова сделать отладку удобной.
Прочие улучшения:
Официальная поддержка vSphere и vSAN 8.3 API, а также Veeam Backup & Replication v12
Добавлен выбор версии в панель мониторинга VMware Evo Version
Добавлена многострочная панель в панель мониторинга репозиториев Veeam
Обработка учетных записей с очень ограниченными правами
Опция использования MAC-адреса вместо Client-ID при использовании DHCP
Добавлено имя хоста гостевой ОС в инвентаризацию виртуальных машин
Релиз St. Olga (0.99j) от 12 февраля 2024
В этой версии авторы добавили официальную поддержку новых API vSphere и vSAN 8.2, а также Veeam Backup & Replication v11+.
Новые возможности:
Поддержка Veeam Backup & Replication
Автоматическое слияние метрик ВМ и ESXi между кластерами (функция DstVmMigratedEvent в VROPS)
Количество путей до HBA
PowerShell Core 7.2.17 LTS
PowerCLI 13.2.1
Grafana 8.5.9 (не 8.5.27 из-за ошибки, появившейся в v8.5.10)
Ubuntu 20.04.6 LTS
Улучшения и исправления:
Метрика IOPS для виртуальных машин
Инвентаризация VMware VBR
История инвентаризации
Панель мониторинга эволюции версий активов VMware
Исправлено пустое значение datastoreVMObservedLatency на NFS
Различные исправления ошибок
SexiGraf теперь поставляется только в виде новой OVA-аппаратной версии, больше никаких патчей (за исключением крайних случаев). Для миграции необходимо использовать функцию Export/Import, чтобы извлечь данные из вашей предыдущей версии SexiGraf и перенести их в новую.
Актуальная версия SexiGraf доступна для бесплатной загрузки на странице Quickstart.
Прошло довольно много времени с момента последнего крупного выпуска RabbitMQ — версия 3.0 была запущена еще в ноябре 2012 года. Хотя ожидание следующего большого обновления могло показаться долгим, за это время произошло немало событий. Вместе с несколькими приобретениями команда VMware Tanzu RabbitMQ представила значительные функции и улучшения в промежуточных выпусках. Сегодня RabbitMQ является ключевым компонентом портфеля VMware Tanzu Data Solutions в VMware Tanzu. Приверженность Broadcom к сообществу с открытым исходным кодом также имеет важное значение, поскольку все участники основной инженерной команды являются сотрудниками Broadcom.
Неудивительно, что самая значительная функция RabbitMQ 4.0 является одновременно и нарушением обратной совместимости и в значительной степени невидима для пользователей, однако она критически важна для будущей устойчивости RabbitMQ. Как и многие другие продукты такого типа, RabbitMQ имеет хранилище метаданных в своей основе. Это хранилище используется для хранения определений топологии сообщений, пользователей, виртуальных хостов (vhosts), очередей, обменов, байндингов и параметров выполнения — оно жизненно важно для работы брокера сообщений.
Старое хранилище метаданных Mnesia использовалось столько же, сколько существует RabbitMQ. Как и следовало ожидать, за последние 17 лет в функциональности RabbitMQ произошло множество изменений, и многие функции были улучшены. Новое хранилище метаданных в RabbitMQ 4.0 (Khepri) использует тот же проверенный raft-based алгоритм, который уже несколько лет поддерживает безопасность данных в очередях Quorum Queue. Это делает систему очень устойчивой к разделению сети, что, в свою очередь, делает продукт Tanzu RabbitMQ более надежным.
Другие важные преимущества заключаются в том, что Khepri более эффективен в выполнении задач обслуживания, таких как удаление очередей или обменов, что ведет к общему улучшению производительности ядра Tanzu RabbitMQ. Эти улучшения производительности также прокладывают путь для дальнейших улучшений возможностей кластеризации Tanzu RabbitMQ. Пользователи могут включить Khepri с помощью опционального флага функции, так что никто не будет вынужден использовать эту технологию, если это не требуется. Разумеется, никаких изменений в коде не требуется при его включении, и RabbitMQ автоматически обрабатывает миграцию с Mnesia на Khepri.
Что касается производительности, в этом выпуске протокол AMQP 1.0 включен в ядро RabbitMQ. Это не означает, что старый протокол AMQP 0.9.1 не будет поддерживаться — это просто значит, что теперь можно выбрать более современный и стандартизированный протокол. Поддержка этой новой версии, опубликованной OASIS, укрепляет многопротокольный подход RabbitMQ и увеличивает его универсальность. В соответствии с другими "нативизациями" поддержка AMQP 1.0 также обеспечивает такие же улучшения производительности, которые были достигнуты при внедрении "нативного" MQTT в версиях 3.12 (MQTTv3) и 3.13 (MQTTv5).
На самом деле, пропускная способность (throughput) AMQP 1.0 между версиями 3.13 и 4.0 более чем удвоилась для классических очередей и очередей Quorum, а также для потоков. Как мы видели с нативной реализацией MQTT, такой подход к протоколам ведет к меньшему потреблению памяти на соединение. Это значит, что кластеры RabbitMQ теперь могут обрабатывать более чем в два раза больше соединений AMQP 1.0 по сравнению с предыдущими выпусками. Для получения дополнительной информации об этих улучшениях производительности, пожалуйста, ознакомьтесь с этой статьей в блоге.
Ранее пользователи не могли воспользоваться возможностями управления топологией, определенными в спецификации AMQP 1.0, что требовало заранее заданных очередей, байндингов и обменов. Такая жесткая настройка ограничивала ключевую силу RabbitMQ — его гибкие маршрутизационные возможности. Однако в версии 4.0 клиентские приложения теперь могут самостоятельно объявлять, удалять, очищать, связывать или отсоединять как очереди, так и обмены при использовании AMQP 1.0. Можно даже выполнять команду "get queue", которая предоставляет полезную информацию о лидере очереди и ее репликах в случае очередей Quorum. Эти клиентские библиотеки значительно помогают разработчикам извлекать максимум из протокола с минимальными усилиями. Например, такие функции, как подтверждения отправителя, становятся очень простыми. На сегодняшний день доступны клиенты Java и .NET, а скоро появятся и другие.
Нечасто удаление функции вызывает столько внимания, как удаление классических зеркальных очередей (Classic Mirrored Queues) в RabbitMQ. Несмотря на то, что эти старые зеркальные очереди были устаревшими более 3 лет, многие разочарованы их окончательным удалением. Хорошая новость заключается в том, что, хотя зеркалирование и было удалено, любые очереди, которые были зеркальными, не будут полностью удалены в версии 4.0, только их зеркальная часть. Также стоит отметить, что пользователям не обязательно использовать зеркалирование для публикации или потребления сообщений с конкретных узлов. Фактически, даже после удаления зеркальной очереди можно публиковать сообщения или потреблять их из очереди на любом узле в том же кластере RabbitMQ. Таким образом, приложения могут использовать те же классические очереди, что и раньше. Классические очереди продолжают поддерживаться без каких-либо изменений, нарушающих совместимость с клиентскими библиотеками. Для обеспечения дальнейшей безопасности данных реплицируемыми типами остаются очереди Quorum и потоки, обе из которых являются очень зрелыми технологиями. Дополнительную информацию о том, как мигрировать с классических зеркальных очередей на очереди Quorum, можно найти в этой статье в блоге.
Инженерная команда RabbitMQ продолжает развивать очереди Quorum, чтобы они работали быстрее и безопаснее, чем раньше. Ранее пользователи могли назначать до 255 приоритетов с помощью классических зеркальных очередей, однако это путь к полному приоритетному хаосу и путанице. В спецификации JMS для AMQP 1.0 определено всего два приоритета — нормальный и высокий.
Это то, что было реализовано в очередях Quorum для версии 4.0. Любое значение приоритета между 0 и 4 (включительно) считается нормальным приоритетом. Значения выше 4 считаются высоким приоритетом, а если издатель не указывает приоритет сообщения, предполагается значение 4 (нормальный приоритет). Что делать, если пользователям нужно больше контроля? Возможно, пришло время пересмотреть определения приоритетов сообщений. Приоритеты часто наследуются от старых систем и редко пересматриваются, как видно из спецификации JMS. Если это не удается разрешить, одним из решений является использование нескольких очередей — теперь это стало проще благодаря более быстрому времени загрузки очередей Quorum в RabbitMQ 4.0 и программной декларации AMQP 1.0. Кроме того, в очередях Quorum теперь установлено значение по умолчанию для ограничения на доставку — 20, а также приоритеты для одного активного потребителя (Single Active Consumer).
Добавлен и новый тип обмена — Random Exchange. В основном предназначен для использования в сценариях "запрос-ответ", в которых сообщения всегда доставляются в локальную очередь (чтобы уменьшить задержку при публикации). Если к тому же обмену подключено несколько локальных очередей, для доставки сообщения будет выбрана одна из них случайным образом.
Для пользователей Kubernetes добавлена новая диаграмма Helm, которая развертывает как операторы Kubernetes с открытым исходным кодом, так и коммерческие операторы кластеров и топологии Tanzu. Кроме того, теперь в определениях пользовательских ресурсов Kubernetes (Custom Resource Definitions) поддерживаются регулярные выражения, что позволяет пользователям определять диапазон виртуальных хостов (vhosts) вместо их явного объявления каждый раз.
Функции устойчивости репликации "Горячий резерв" (Warm Standby Replication) также получили улучшения в этом выпуске. В версии 3.13 был добавлен конфигурационный файл, облегчающий пользователям настройку и конфигурацию WSR, который в версии 4.0 был улучшен поддержкой списков и шаблонов для виртуальных хостов и т. д. Поддержка секретов теперь доступна через тот же конфигурационный файл, чтобы помочь обеспечить дополнительную безопасность для репликационной связи между верхним и нижним кластерами; в настоящее время поддерживается Hashicorp Vault. Пользователи также могут помечать конкретные определения shovel и federation для синхронизации в рамках процесса репликации горячего резерва. Оператор Standby Replication для Kubernetes заменен этим конфигурационным файлом, что упрощает настройку WSR независимо от среды.
Таким образом, RabbitMQ 4.0 приносит несколько ключевых улучшений, особенно в области совместимости и устойчивости. Наиболее заметное для пользователей изменение — внедрение AMQP 1.0 как основного протокола с значительными улучшениями пропускной способности и подключений. Этот выпуск и его дополнительные клиентские библиотеки открывают путь к дальнейшему развитию RabbitMQ, что позволит ему оставаться наиболее широко используемым брокером сообщений во всем мире на долгие годы.
За месяц до VMware Explore 2024 в Лас-Вегасе компания VMware представила новую версию PowerCLI 13.3. В этом выпуске исправлены многочисленные ошибки, добавлены улучшения и новые возможности, такие как командлет для отчета о привилегиях Privilege Report и другие. Давайте разберем все детали этой новой версии PowerCLI. А о возможностях прошлой версии PowerCLI 13.2 вы можете почитать у нас тут.
Улучшения VCF SDDC Manager
В версии 13.3 было добавлено два новых командлета:
Wait-VcfTask — позволяет ожидать завершения асинхронных операций, например задач.
Wait-VcfValidation — позволяет ожидать завершения конкретных операций проверки VCF, например операций проверки доменов.
Улучшения vSphere
Был добавлен новый командлет для записи проверок привилегий, которые происходят для указанных сессий при выполнении указанного блока сценария:
Get-VIPrivilegeReport
Улучшения VSAN
В PowerCLI 13.3 было добавлено два новых командлета для настройки пороговых значений алармов:
New-AlarmTriggerArgument — создает новый триггер действия для указанного аларма.
Get-AlarmTriggerArgumentAttributeName — выводит имена атрибутов аргумента триггера тревоги для события типа "vsan.health.ssd.endurance".
Также было обновлено несколько существующих командлетов:
Get-VsanSpaceUsage — добавлена поддержка нового атрибута "коэффициент эффективности использования пространства" в типе возвращаемых данных.
Set-VsanClusterConfiguration — добавлен новый параметр "vsanmaxenabled" для включения службы vSAN Max.
Get-VsanClusterConfiguration — добавлен новый параметр "vsanmaxenabled" для проверки, включен ли кластер vSAN как vSAN Max.
Улучшения HSX
В PowerCLI 13.3 добавлено два новых командлета для настройки гостевых операционных систем:
New-HCXGuestOSNetworkCustomization - создает объект для настройки сети, который является частью кастомизации гостевой ОС.
New-HCXGuestOSCustomization - создает объект для кастомизации гостевой ОС.
Следующие два командлета обновлены для использования вышеупомянутых новых командлетов в качестве параметров:
New-HCXMigration — для настройки гостевой ОС на уровне миграции.
New-HCXMobilityGroupConfiguration — для настройки гостевой ОС на уровне группы.
Улучшения Image Builder
В PowerCLI 13.3 теперь есть поддержка Python версии 3.12. Наряду с этим добавлена поддержка OpenSSL 3.0. Поддержка OpenSSL 1.1 прекращена из-за завершения срока поддержки, объявленного в сентябре 2023 года.
Обновленные модули SDK
Следующие модули обновлены в PowerCLI 13.3:
Модули vSphere обновлены до vSphere 8.0U3.
Модули NSX обновлены до NSX 4.2.0.0.
Модули SRM и vSphere Replication обновлены до версии 9.0.1.
Модуль VCF обновлен до VMware Cloud Foundation 5.2.
Для получения более подробной информации, пожалуйста, ознакомьтесь с подробным журналом изменений и Release Notes для PowerCLI 13.3.
Продолжаем рассказывать об обновлениях проверенных решений VMware Validated Solutions, которые произошли в мае этого года. Напомним, что о мартовских обновлениях мы рассказывали вот тут.
Инфраструктура Private AI Ready для VMware Cloud Foundation
Инфраструктура Private AI Ready, готовая к использованию в VMware Cloud Foundation, представляет собой хорошо спроектированное проверенное решение, предоставляющее предприятиям инфраструктуру с поддержкой AI и GPU для создания платформы AI для дата-сайентистов и инженеров по машинному обучению, использующую VMware Cloud Foundation в качестве базового слоя ПО.
Отчетность о состоянии и мониторинг для VMware Cloud Foundation
Проверенное решение для отчетности о состоянии и мониторинга для VMware Cloud Foundation теперь поддерживает узлы Dell VxRail как для консолидированных, так и для стандартных архитектур.
Private Cloud Automation для VMware Cloud Foundation
Проверенное решение для автоматизации частного облака для VMware Cloud Foundation теперь поддерживает VMware Aria Automation 8.16.2.
Защита сайтов и восстановление после аварий для VMware Cloud Foundation
Проверенное решение Site Protection and Disaster Recovery for VMware Cloud Foundation для VMware Cloud Foundation теперь поддерживает VMware Site Recovery Manager 9.0 и vSphere Replication 9.0.
Управление идентификацией и доступом для VMware Cloud Foundation
Проверенное решение для управления идентификацией и доступом для VMware Cloud Foundation теперь предоставляет процедуру для полной автоматизации с использованием нового меню проверенных решений, предоставленного модулем PowerShell для VMware Validated Solutions. См. Реализация управления идентификацией и доступом с использованием автоматизации PowerShell.
Модуль PowerShell, написанный для поддержки автоматизации многих процедур, связанных с реализацией проверенных решений VMware для VMware Cloud Foundation.
Модуль помогает снизить количество ошибок, обеспечивая согласованность и надежность, а также ускоряет время развертывания этих решений. Команды модуля упрощают и автоматизируют этапы развертывания и конфигурации с использованием API продуктов или инструментов командной строки.
Основные моменты нового релиза:
Добавлено Start-ValidatedSolutionsMenu вместе с подменю для облегчения и ускорения использования.
Добавлены функции для проверки предварительных условий для каждого проверенного решения.
Добавлены функции для генерации подписанных сертификатов от Microsoft Certificate Authority для VMware Aria Suite и Site Recovery Manager, устраняя необходимость в использовании CertGenVVS.
Добавлена поддержка настройки ролей в VMware Aria Suite Lifecycle.
Недавно компания VMware представила обновленный список изменений, произошедших в решении VMware Validated Solutions в марте этого года. Давайте посмотрим но основные из них:
Добавлена поддержка VMware Cloud Foundation 5.1.1 для всех решений VMware Validated Solutions
Обновлен механизм управления паролями для последней версии Photon OS
Некоторые виртуальные модули были перенесены с Photon v3 на v4, что привело к изменениям в настройках сложности пароля и политик блокировки аккаунтов, в результате чего соответствующие разделы каждого решения были изменены для отражения новых конфигурационных файлов. Следующие Validated Solutions были обновлены:
Intelligent Operations Management for VMware Cloud Foundation
В решении Intelligent Operations Management for VMware Cloud Foundation обновилась процедура "Развертывание VMware Aria Operations с использованием VMware Aria Suite Lifecycle для управления интеллектуальными операциями в VMware Cloud Foundation" в целях автоматической настройки правил Anti-Affinity для vSphere, при этом был удален ручной шаг "Настройка правил Anti-Affinity DRS vSphere модулей VMware Aria Operations для управления интеллектуальными операциями в VMware Cloud Foundation".
Процедуры реализации теперь включают дополнительную автоматизацию, предоставляемую PowerValidatedSolutions:
Настройка интеграции VMware Cloud Foundation для управления интеллектуальными операциями в VMware Cloud Foundation (Add-vROPSAdapterVcf).
Intelligent Network Visibility for VMware Cloud Foundation
Применение пакета поддержки продукта к VMware Aria Suite Lifecycle для управления интеллектуальными операциями в VMware Cloud Foundation
Private Cloud Automation for VMware Cloud Foundation
Процедуры реализации теперь включают дополнительную автоматизацию, предоставляемую PowerValidatedSolutions:
Определение пользовательских ролей в vSphere для VMware Aria Automation и VMware Aria Automation Orchestrator для автоматизации частного облака в VMware Cloud Foundation (Copy-vSphereRole)
Site Protection and Disaster Recovery for VMware Cloud Foundation
Процедуры реализации теперь включают дополнительную автоматизацию, предоставляемую PowerValidatedSolutions:
Настройте репликацию, создайте группу защиты и план восстановления для VMware Aria Suite Lifecycle и кластеризованного Workspace ONE Access для защиты сайта и восстановления после сбоев для VMware Cloud Foundation (Add-vSphereReplication, Add-ProtectionGroup и Add-RecoveryPlan).
Настройте план восстановления для VMware Aria Suite Lifecycle и кластеризованного Workspace ONE Access для защиты сайта и восстановления после сбоев для VMware Cloud Foundation (Set-RecoveryPlan).
Настройте репликацию, создайте группу защиты и план восстановления для кластера аналитики VMware Aria Operations для защиты сайта и восстановления после сбоев для VMware Cloud Foundation (Add-vSphereReplication, Add-ProtectionGroup и Add-RecoveryPlan).
Настройте план восстановления для VMware Aria Operations для защиты сайта и восстановления после сбоев для VMware Cloud Foundation (Set-RecoveryPlan).
Настройте репликацию, создайте группу защиты и план восстановления для VMware Aria Automation для защиты сайта и восстановления после сбоев для VMware Cloud Foundation (Add-vSphereReplication, Add-ProtectionGroup и Add-RecoveryPlan).
Настройте план восстановления для VMware Aria Automation для защиты сайта и восстановления после сбоев для VMware Cloud Foundation (Set-RecoveryPlan).
Cloud-Based Workload Protection for VMware Cloud Foundation
Модуль помогает уменьшить воздействие ошибок вследствие человеческого фактора, обеспечивает консистентность и надежность, а также ускоряет время развертывания этих решений. Командлеты модуля уменьшают сложность, автоматизируя этапы развертывания и настройки с использованием API продукта или командных инструментов.
Также были добавлены новые командлеты для поддержки развертывания VMware Validated Solutions в один клик.
На днях компания NAKIVO объявила о выпуске бета-версии продукта NAKIVO Backup & Replication v10.11, предназначенного для резервного копирования и репликации виртуальных сред. Напомним, что о возможностях прошлой беты этого продукта мы писали вот тут.
Давайте посмотрим, что нового будет в NAKIVO v10.11:
Оповещения и отчеты для мониторинга - можно создавать настраиваемые алармы для обнаружения подозрительной активности и получать полные отчеты о виртуальных машинах, хостах и хранилищах данных VMware.
Резервное копирование для Oracle RMAN на Linux - можно защищать БД Oracle на Linux от потери данных с помощью родного унифицированного интерфейса.
Индексация файловой системы - быстрый поиск определенных файлов и папок в резервных копиях для экономии времени во время детального восстановления.
Резервное копирование со снимков хранилища HPE Alletra и HPE Primera - можно оптимизировать производительность, используя нативные снимки массивов для бэкапа виртуальных машин.
Функции In-Place Archive Mailbox, Litigation Hold и поддержка In-Place Hold - можно защищать дополнительные категории в почтовых ящиках Exchange Online, чтобы упростить соответствие требованиям по сохранению данных.
Универсальная передача - улучшайте эффективность рабочего процесса и уменьшайте нагрузку на сеть, используя один универсальный транспортер для нескольких типов рабочих нагрузок на одном хосте.
Скачать NAKIVO Backup & Replication v10.11 Beta можно по этой ссылке.
Недавно компания VMware обновила решение Cloud Director Availability 4.7, которое предназначено для создания резервной инфраструктуры в одном из публичных облаков на основе VMware Cloud Director (так называемая услуга Disaster-Recovery-as-a-Service, DRaaS). Напомним, что о прошлой версии этого продукта мы писали вот тут.
Новый механизм репликации
До настоящего момента VMware Cloud Director Availability использовал независимые (independent) диски при репликации рабочих нагрузок в облака Cloud Director. Однако это не является их изначальным назначением, что может оказать отрицательное влияние на механику репликации в определенных случаях.
Для уменьшения действия этого фактора и дальнейшего улучшения стабильности и оперативности, а также для обеспечения возможности будущих улучшений, введена система отслеживания репликации Replication Tracking VM (RT VM). Она позволяет использовать новый способ репликации виртуальных машин, совместимый с продуктом Cloud Director Availability 4.7, который зарегистрирован в Cloud Director 10.5+.
Запущенные репликации не будут затронуты этим изменением после обновления VMware Cloud Director Availability. Существует опция для их миграции с независимых дисков на RT VM через пользовательский интерфейс VMware Cloud Director Availability.
Все новые репликации будут использовать этот новый механизм размещения.
Выбор политики хранения
VMware Cloud Director Availability 4.7 получил две новые функции, связанные с выбором политики хранения:
Выбор политики хранения для каждого диска
Переназначение политики хранения во время восстановления рабочей нагрузки
Выбор политики для каждого диска
В предыдущих версиях VMware Cloud Director Availability при выборе политики для репликации применялись одни и те же настройки для всех ее дисков. В версии 4.7 вы теперь можете указать политику для каждого диска, сохраняя при этом остальные функции, такие как исключение диска или использование Seed VM.
Эта функция доступна как для облаков Cloud Director, так и для vSphere с одним отличием - для облаков vSphere вы можете выбрать политику хранения и хранилище размещения для каждого диска.
При использовании seed VM репликация будет использовать ее настройки хранилища, и вы не сможете их указать.
Переназначение политики во время восстановления рабочей нагрузки
С учетом оптимизации затрат часто принято использовать медленное, но более дешевое хранилище для данных. Это актуально и для репликаций, где с течением времени может накапливаться большой объем данных.
Однако скорость хранилища может негативно сказаться на производительности рабочей нагрузки при ее переключении в случае сбоя. Чтобы сэкономить клиентам сложный выбор того, где именно пойти на уступки, VMware Cloud Director Availability 4.7 позволяет использовать конкретные настройки хранилища при начальной настройке репликации, а затем выбрать другие настройки при восстановлении реплик.
Эта новая функция доступна как для облаков vSphere, так и для облаков Cloud Director.
Предварительная проверка выполнения планов восстановления
При использовании планов восстановления довольно неприятно достичь определенного этапа их выполнения и обнаружить, что некоторые настройки репликации не настроены, что приводит к неудачному завершению плана. Предварительная проверка выполнения планов восстановления убирает это неудобство и уменьшает время, затрачиваемое на проверку обязательных конфигураций, необходимых Cloud Director Availability для завершения репликации или набора репликаций.
Эти проверки учитывают значительные изменения в инфраструктуре облака, проверяют настройки размещения и наличие недостающих настроек восстановления, а также доступность исходного сайта для случаев миграции.
Эта информация доступна в новой вкладке "Health", которая присутствует в каждом плане восстановления при его выборе. Там вы можете увидеть, когда была проведена последняя проверка, а также доступные действия для устранения обнаруженной проблемы.
Механизм vSphere DR и поддержка миграций Seed VM
В рамках улучшений по обеспечению равенства функций для точек назначения vSphere и Cloud Director, теперь можно выбрать начальную виртуальную машину (Seed VM) при репликации рабочих нагрузок в облака vSphere.
Улучшения для облаков VMware Cloud Director
Появилось несколько новых функций, которые решают проблемы для поставщиков облачных услуг и их клиентов, которые реплицируют рабочие нагрузки в облака назначения Cloud Director:
Передача меток безопасности NSX, связанных с реплицированной виртуальной машиной при инициировании миграции/восстановления между двумя облаками, работающими на VMware Cloud Director 10.3+.
Автовыбор политики сайзинга при cloud-to-cloud - если виртуальной машине назначена политика сайзинга на исходном сайте, и на назначенном сайте существует политика с таким же именем, она будет автоматически выбрана при настройке репликации.
Управление видимостью удаленных облачных сайтов - поставщики облачных услуг могут контролировать, какие партнерские сайты будут видны для каких организаций. Если сайт, на котором активны репликации, скрыт, они будут продолжать отображаться в пользовательском интерфейсе, но невозможно будет создавать новые репликации в/из скрытого сайта.
Управление политиками для направлений репликации - доступные средства управления расширяются еще одной новой опцией для поддержания возможного направления операций репликации для клиента облака. С ее помощью поставщики облачных услуг могут ограничить клиентов в защите рабочих нагрузок, работающих в облаке, только в направлении их собственного датацентра.
Более подробную информацию о VMware Cloud Director Availability 4.7 можно получить по этой ссылке.
Таги: VMware, vSphere, Cloud, Availability, Director, Update, DR
На прошедшей недавно конференции Explore 2023 Europe компания VMware объявила о предстоящем запуске решения VMware Live Recovery, которое обеспечит защиту от программ-вымогателей (Ransomware) и восстановление после катастроф в VMware Cloud через единую консоль.
Платформа VMware Live Recovery разработана, чтобы помочь организациям защищать свои приложения и данные в инфраструктуре VMware от множества угроз разного типа, включая атаки программ-вымогателей, сбои инфраструктуры, человеческие ошибки и многое другое.
VMware Live Recovery будет предоставлять клиентам:
Безопасное восстановление после кибератак - это позволит организациям с уверенностью и быстро восстановиться после атак программ-вымогателей, зашифровавших и заблокировавших данные.
Единая защита - Live Recovery предоставит единую консоль для управления функциями защиты от Ransomware и восстановления после катастроф, упрощая администрирование крупных систем.
Упрощенное использование - продукт предложит гибкую лицензию для различных случаев использования и облачных решений, упрощая для организаций получение необходимой защиты.
VMware Live Recovery будет идеальным решением для администраторов, ответственных за устойчивость инфраструктуры, и команд безопасности, которые также управляют киберугрозами. Это будет важный инструмент для организаций, использующих VMware Cloud для работы своих критически важных приложений.
Что нового в концепции VMware Live Recovery?
VMware Live Recovery будет отличаться от других решений на рынке в ряде аспектов. Во-первых, это будет интегрированное решение, предоставляющее единую защиту от программ-вымогателей и восстановления после катастроф для всей гибридной инфраструктуры. Это означает, что организации смогут управлять своими потребностями в защите в рамках нескольких облаков с помощью единой консоли, упрощая управление и снижая затраты.
Во-вторых, VMware Live Recovery разработан изначально, чтобы помочь организациям безопасно восстанавливаться после атак программ-вымогателей. Для этого будут использоваться многие современные техники, включая неизменяемые снимки, изолированную среду восстановления VMware (isolated recovery environment, IRE) для тестирования и проверки зараженных виртуальных машин, руководство по рабочим процессам и встроенный антивирус нового поколения, а также средства анализа поведения для выявления современных программ-вымогателей.
Наконец, VMware Live Recovery предложит гибкую лицензию по подписке для различных случаев использования и облачных решений. Это упростит для организаций получение необходимой защиты, с возможностью добавления или изменения функциональности в соответствии с изменяющимися потребностями или требованиями бизнеса.
Объединенное решение
VMware Live Recovery объединит два проверенных решения VMware в единую консоль и поддержку организации. Клиенты получат доступ к функциональным возможностям VMware Site Recovery Manager и VMware Cloud Disaster Recovery с восстановлением после атак программ-вымогателей. Кроме того, клиенты могут выбирать между моделями развертывания, сохраняя при этом единую консоль, с гибкостью для изменяющихся бизнес-потребностей и уверенностью в поддержке от единого производителя.
Как VMware Live Recovery может помочь вашей организации?
Решение сможет помочь вашей организации различными способами. Оно обеспечит единую защиту с помощью восстановления после атак программ-вымогателей и восстановления после катастроф в VMware Cloud в одной консоли (Secure Cyber Recovery), которое позволяет уверенно и быстро восстанавливаться после большинства атак на данные. Кроме того, модель Simplified Consumption позволит гибко лицензировать использование сценариях и инфраструктурах.
Более подробная информация о продукте должна появиться в ближайшее время.
В рамках проходившей недавно конференции Explore 2023 Europe компания VMware анонсировала релиз новой версии своего основного фреймворка для управления виртуальной инфраструктурой с помощью сценариев - PowerCLI 13.2. Напомним, что о прошлой версии этого пакета - PowerCLI 13.1 - мы писали вот тут.
Этот релиз предоставляет официальную поддержку VMware Cloud Foundation (VCF) в PowerCLI, а также новые функции для vSphere, vSAN и VMware Cloud.
1. Новые SDK-модули для VCF
VMware Cloud Foundation (VCF) - это интегрированная платформа, объединяющая полный спектр программно-определяемых сервисов в единую систему. По мере того, как все больше клиентов VMware начинают использовать VCF, увеличивается и спрос на автоматизацию через CLI. До сих пор единственным вариантом был модуль PowerVCF с открытым исходным кодом, но с PowerCLI 13.2 было добавлено два официальных модуля VCF – VMware.Sdk.Vcf.CloudBuilder и VMware.Sdk.Vcf.SddcManager. Это SDK-модули, использующие ту же технологию, что и модули PowerCLI SDK для vSphere Automation, NSX, SRM и API vSphere Replication. Как и в случае со всеми SDK-модулями, примеры PowerCLI можно найти непосредственно в документации REST API для VCF.
2. Новые функции управления жизненным циклом vSphere
В PowerCLI 13.2 было добавлено два новых командлета для vLCM:
Export-LcmVMHostDesiredState экспортирует желаемое состояние хоста vSphere Lifecycle Manager
New-OfflineBundle создает автономный пакет, соответствующий требованиям vLCM, на основе введенных данных о хранилищах и спецификации программного обеспечения.
3. Новые функции vSAN
В PowerCLI 13.2 был добавлен новый командлет Get-VsanPerformanceContributor в модуль VMware.VimAutomation.Storage. Он позволяет получить список наиболее значимых объектов, влияющих на производительность vSAN. Также был расширен вывод командлета Get-VsanSpaceUsage за счет свойства EsaObjectOverheadGB, которое предоставляет информацию о дополнительных накладных расходах для объектов vSAN ESA на хранение метаданных и обеспечение высокой производительности.
4. Новые функции VMware Cloud
В PowerCLI 13.2 были расширены командлеты New-VmcSddc и New-VmcSddcCluster за счет добавления поддержки хостов I4I.
5. Обновленные SDK-модули
В PowerCLI 13.2 были обновлены все модули, предоставляющие привязки к API. А именно:
Модули vSphere обновлены до версии vSphere 8.0 Update 2
Модули NSX обновлены до версии NSX 4.1.2
Модули SRM и vSphere Replication обновлены до версии 8.8
Модуль Horizon обновлен до VMware Horizon 8 2306
Скачать последнюю версию фреймворка VMware PowerCLI 13.2 можно по этой ссылке.
Многие администраторы самого мощного решения для резервного копирования и репликации виртуальных и физических сред Veeam Backup and Replication в курсе, что скоро выйдет версия 12.1, где будет множество новых возможностей, несмотря на минорное продвижение номера версии.
Одной из суперполезных фич станет новый Veeam AI Assistant, который был полностью переработан и теперь позволяет быстро и просто найти, как выполнить любое действие, связанное с защитой данных виртуальной инфраструктуры:
Кстати, для получения помощи по продуктам Veeam вы можете использовать и обычный ChatGPT. Об этом рассказано вот в этой статье. Работает вполне неплохо, например, вот как можно рассчитать сайзинг компонентов инфраструктуры резервного копирования:
Этот расчет вы можете сравнить с результатами официальных утилит от Veeam, которые используются для задач сайзинга:
На днях компания NAKIVO выпустила бета-версию обновленного продукта для резервного копирования и репликации виртуальных машин NAKIVO Backup & Replication v10.10 Beta. Напомним, что о прошлой версии Backup & Replication v10.9 мы писали вот тут.
Теперь вы можете создавать реплики виртуальных машин на платформе VMware vSphere, включая данные приложений и файлы конфигурации, и поддерживать их актуальность в соответствии с исходной ВМ по мере внесения изменений в почти реальном времени. Достигайте минимальных показателей RTO и RPO в рамках временного окна в 1 секунду.
Вы можете использовать функциональность репликации в реальном времени и аварийное переключение на реплики для:
Обеспечения доступности критически важных рабочих нагрузок и достижения нулевого простоя во время катастрофы или атаки вымогателей.
Минимизации периода переключения и избежания простоя, связанного с миграцией данных.
Прежде чем приступить к настройке задания репликации в реальном времени для ВМ, убедитесь, что выполнены следующие предварительные условия для исходного и целевого хостов.
Исходные хосты:
Установите инструмент I/O Filter на кластер хоста VMware (на исходном хосте). Подробнее об этом тут.
Чтобы позволить I/O Filter обрабатывать исходные ВМ, которые вы хотите реплицировать, вы должны применить настроенную политику хранения I/O Filter к ВМ или создать политику, если у вас её нет.
Целевые хосты:
Разверните узел NAKIVO Backup & Replication (Transporter) в качестве виртуального модуля (Appliance) на VMware vSphere на целевом хосте ESXi (для реплицированной ВМ). Подробнее смотрите на этой странице.
Для запуска заданий репликации в реальном времени на целевом хосте ESXi, вам нужно установить модуль Journal Service на виртуальном модуле под VMware vSphere, развернутом на предыдущем шаге. Подробнее смотрите на странице установка Journal Service.
Скачать бета-версию продукта NAKIVO Backup & Replication v10.10 можно по этой ссылке.
В этом году компания VMware серьезно взялась за доработку своих фреймворков по автоматизации операций в виртуальной инфраструктуре. Это было обусловлено тем, что исторически у VMware накопилось большое количество средств автоматизации, которые когда-то были привязаны к специфическим продуктам и интерфейсам, потом эти продукты эволюционировали, объединялись в различные линейки, а старые интерфейсы продолжали тянуться за разными решениями, управлять которыми до сих пор можно несколькими разными способами, а с учетом различных платформ и вспомогательных сервисов таких способов становится слишком много.

 RSS
RSS